1 介绍
sublime更新两点:
- 许可证更改:Sublime Text License 密钥(注册码)不再与独立的主要版本绑定,而是对购买后 3 年内的所有更新均有效,不过使用更新的版本需要升级 License。
- 支持多 tab 选项卡:方便分割视图,支持通过界面或内置命令行使用。
- 支持 Apple Silicon 和 Linux ARM64:Sublime Text for Mac 包含对 Apple Silicon 处理器的原生支持,Linux ARM64 builds 在树莓派等设备中可用。
- 全新的 UI 界面
- 语境感知自动补全:该版本重写了自动补全引擎,使之能够基于项目中的已有代码提供智能补全。
- 支持 TypeScript、JSX 和 TSX
- 语法定义升级:语法高亮引擎全新升级,能够处理非确定性语法、多行语句、lazy embed 和语法继承。此外,内存使用降低,加载速度更快。
- GPU 渲染:Sublime Text 4 稳定版在渲染界面时,能够在 Linux、Mac 和 Windows 系统中利用 GPU,从而带来流畅的 UI 界面,分辨率最高可达 8K,且消耗的能源更少。
- Python API 升级:Sublime Text 新版本 API 升级至 Python 3.8,同时具备对 Sublime Text 3 软件包的向后兼容性。Python API 新增了许多特性,如允许 LSP 等插件更好地运行。
- 兼容性:Sublime Text 4 完全兼容 Sublime Text 3,可以自动接收旧版本的会话和配置。Sublime Text 还支持 3、4 版本的分开运行。
2 安装
可以直接点击下载sublime进行下载。以下是sublime的官网:
3 汉化
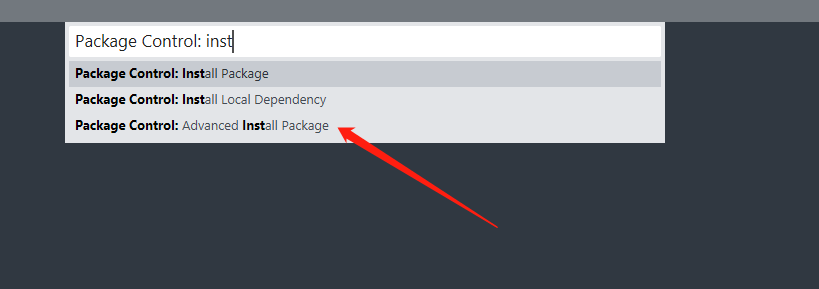
菜单点击Preferences – Package Control,选择 Install Package
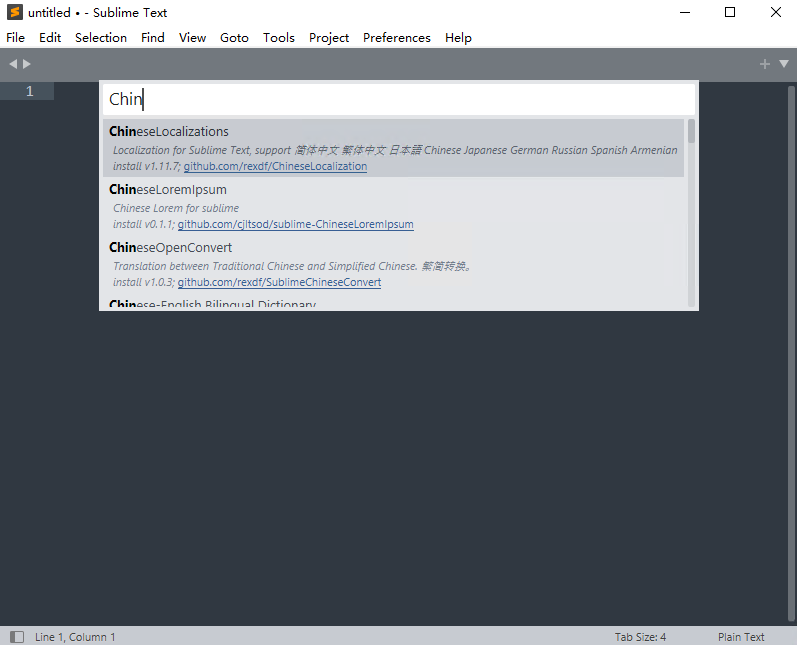
输入 ChineseLocalzations 可见中文包!选中即可安装!
4 破解
不太推荐使用网上的破解工具~ 以下方法亲测可行!
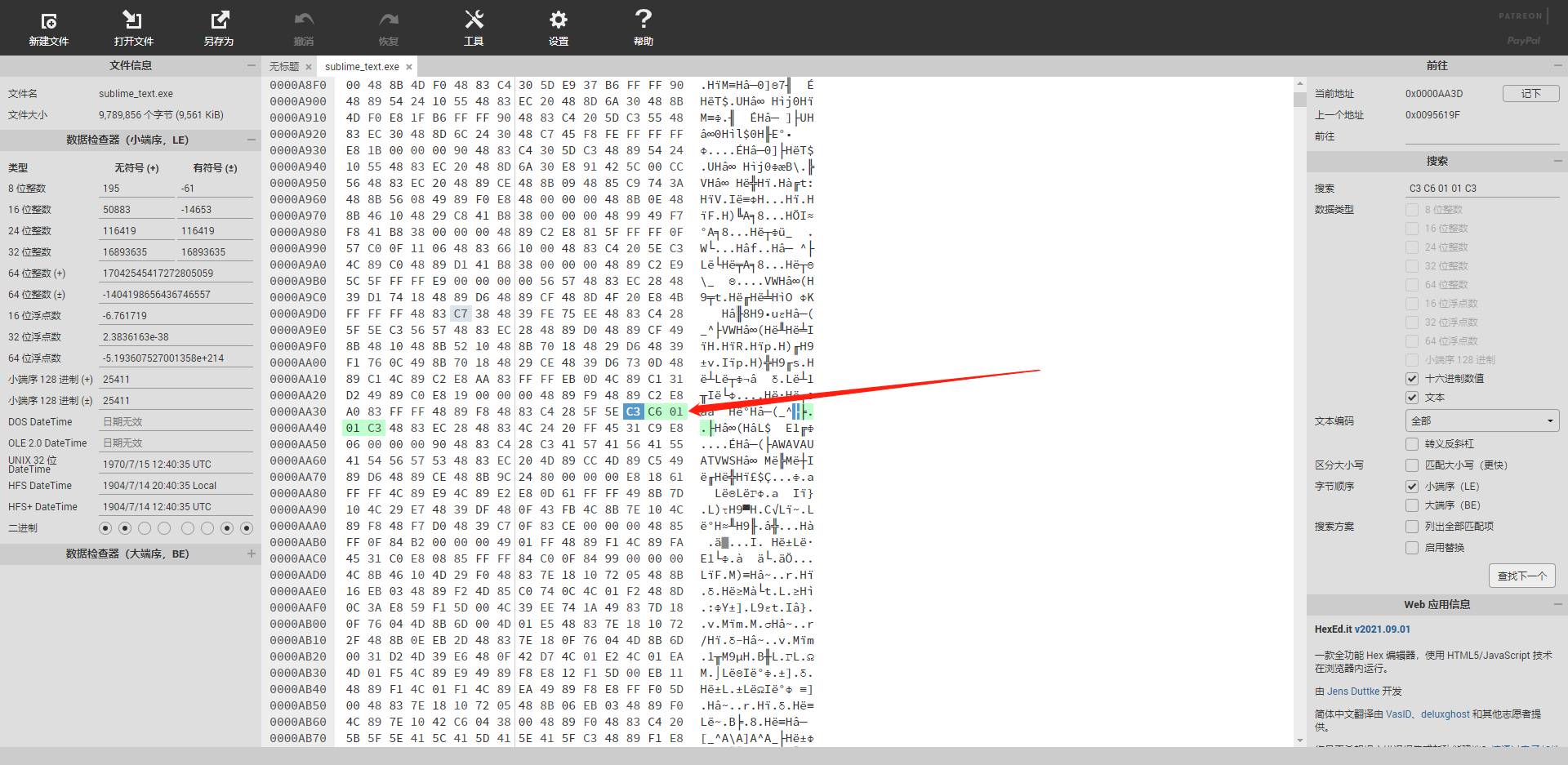
1)在软件的安装目录找到 sublime_text.exe 文件。
2)这里推荐使用: hexed 在线十六进制编辑器,打开 sublime_text.exe 文件。
3)然后查找以下字节并且替换(不同的软件版本替换的内容略有不同,一定要看好软件版本)。
2021年7月14日 最新更新!
软件版本 4113 依此替换下方 2 组字节!(sublime 4113版本下载地址:Windows|mac)
C3 C6 01 00 C3替换为C3 C6 01 01 C351 31 C0 88 05替换为51 b0 01 88 05
软件版本:4107 替换下方 1 组字节!
80 38 00 74 2C 49
替换为FE 00 90 74 2C 49
然后将选择【另存为】将修改后的文件放回原处,即可。
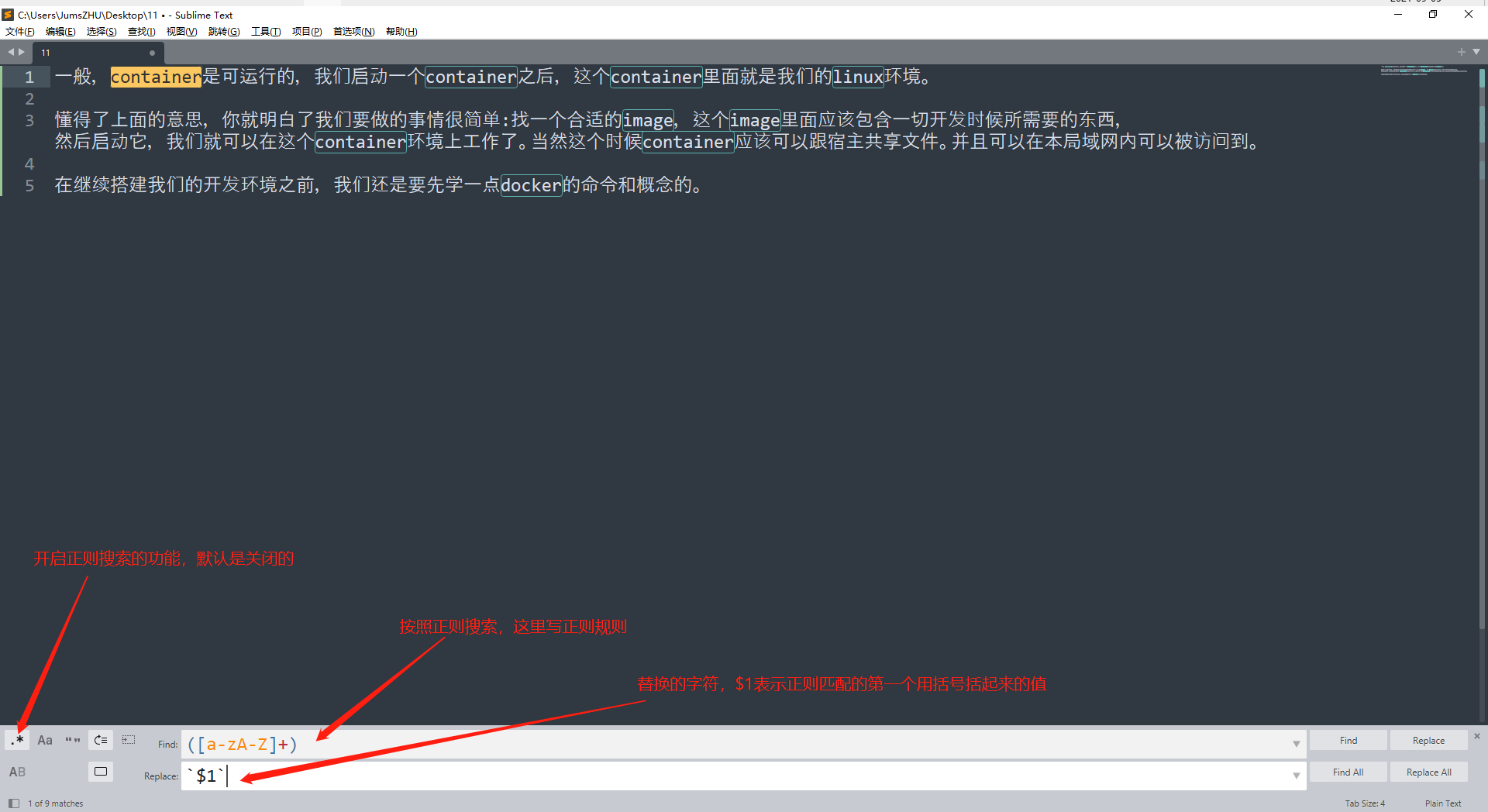
5 正则搜索
这里以这段文字为例:
1 | 一般,container是可运行的,我们启动一个container之后,这个container里面就是我们的linux环境。 |
我需要将其中的英文单词都用`抱起来,因为在markdown中可以高亮显示?
这个需求看起来很简单,如果手动修改,那当然很麻烦,因为都是一些重复的工作,但是如何如何使用python等语言来写一个脚本做这个事情,也不是不可以,就是有点麻烦,经过一番寻找,发现sublime就有这个功能——正则搜索:
注意:
- 如果想使用原值进行替换操作,需要在正则表达式中添加
() $n可以表示第n个变量,$1表示第1个变量,这里的第n个变量的定义是:用括号括起来的部分- 比如:
([a-zA-Z]+)(0-9)+,则使用$1能匹配到前面的全是英文单词的部分,$2能够匹配到后面全是数字的部分
- 比如:
6 正则表达式语法
(1)普通字符
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串 “google runoob taobao” 中所有的 e o u a 字母。 |
| [^ABC] | 匹配除了 […] 中字符的所有字符,例如 [^aeiou] 匹配字符串 “google runoob taobao” 中除了 e o u a 字母的所有字母。 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
(2)非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
(3)特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo\b 中的 ,简单的说就是表示任何字符串的意思。如果要查找字符串中的 符号,则需要对 进行转义,即在其前加一个 \,runo\ob 匹配字符串 runo\ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符”转义”,即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\‘ 匹配 “",而 ‘(‘ 则匹配 “(“。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
(4)限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 ***** 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
以下正则表达式匹配一个正整数,**[1-9]设置第一个数字不是 0,[0-9]*** 表示任意多个数字:
1 | /[1-9][0-9]*/ |
(5)定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
若要在搜索章节标题时使用定位点,下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
1 | /^Chapter [1-9][0-9]{0,1}/ |
Reference
- https://51.ruyo.net/17264.html
- 使用Sublime正则表达式清洗数据
- https://www.runoob.com/regexp/regexp-syntax.html
- Sublime Text 4发布BUILD 4113版本 - Sublime Text3中文网 (bianjiqi.net)
写在最后
欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
 wechat
wechat alipay
alipay bitcoin
bitcoin