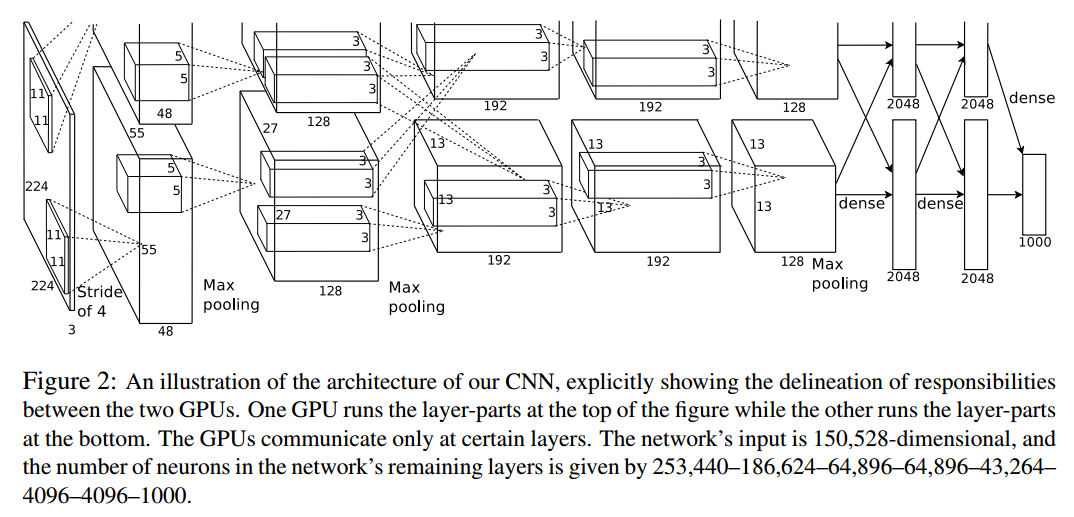
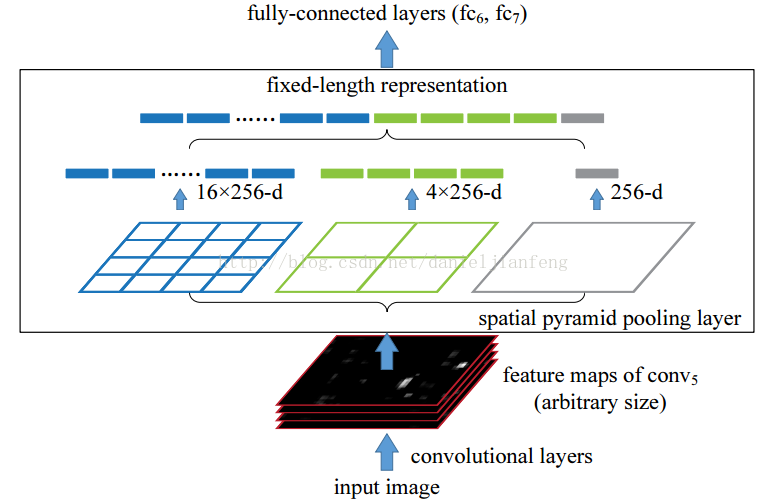
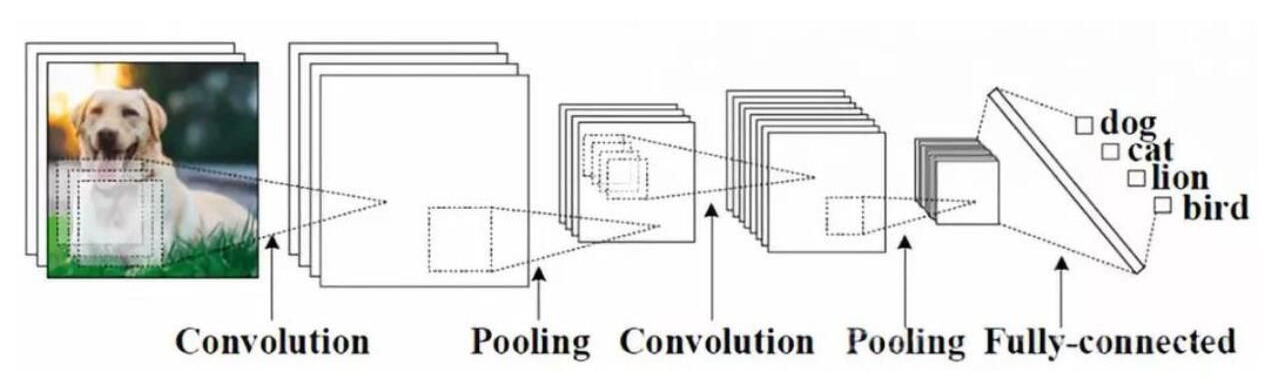
0 A few more concept you need to know
0.1 什么是bagging和boosting|link
bagging:Bagging是Bootstrap Aggregating的英文缩写,是指一种有放回采样
boosting:提升方法(Boosting),是一种可以用来减小监督式学习中偏差的机器学习算法。面对的问题是迈可·肯斯(Michael Kearns)提出的:一组“弱学习者”的集合能否生成一个“强学习者”?弱学习者一般是指一个分类器,它的结果只比随机分类好一点点;强学习者指分类器的结果非常接近真值。
0.2 预测和拟合的区别?
预测:灰色预测的通用性比较强一些,一般场合都可以用,尤其适合那些规律性差且不清楚数据产生机理的情况。
拟合:拟合比较适合于那些清楚数据产生机理,有比较规则的变化趋势的场景,比如已经知道这些数据符合一定的动力学变化规律,这时用指数拟合就比较合适。
在数学建模中,能用拟合的地方尽量用拟合,这样会有具体的函数表达式,更有利于进一步的建模。当然有些问题就是数据的预测,这种情况哪种精度高就用哪种了(建议都用,便于比较),上面所说的最适合的问题,也主要是基于精度考虑的。
0.3 预测和推荐的区别?
0.4 时间序列预测法|link
时间序列预测法其实是一种回归预测方法,属于定量预测,其基本原理是:一方面承认事物发展的延续性,运用过去的时间序列数据进行统计分析,推测出事物的发展趋势;另一方面充分考虑到由于偶然因素影响而产生的随机性,为了消除随机波动产生的影响,利用历史数据进行统计分析,并对数据进行适当处理,进行趋势预测。
0.5 什么有量纲和什么是无量纲?
量纲:是指有具体的单位的量,比如1m/s就是一个量纲量,是矢量。
无量纲:是指没有具体单位的标准化统计量,比如1%等,是标量
归一化:就是将有量纲的量转化成一个无量纲的量,将矢量变成标量。
1 线性回归|link
定义:确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
公式:
举例:
线性回归的目的就是找到一条线,能够使图中的每个点到该直线的举例最短,一般可用最小二乘法进行拟合
2 逻辑回归|link
概念:线性回归可以拟合X与Y之间的关系,但回归模型中Y值是连续的,如果换成一个二分类标签,Y只能取两个值0、1,这时候就不能用线性回归了,这样就有了逻辑回归。
针对Y的值域在区间[0-1]的问题,我们不能寻找到一条完美曲线,用于拟合二分类模型,但我们可以寻找一条完美的S型曲线,S型曲线叫Sigmoid曲线,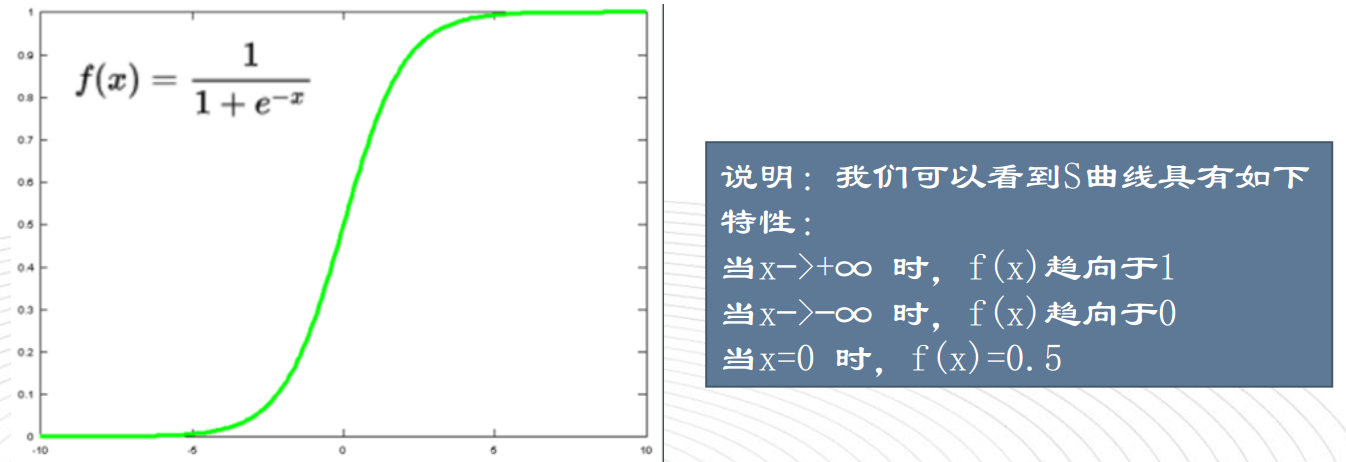
核心原理:
==逻辑回归核心原理是在线性回归的基础上加上一个Sigmoid函数,把训练数据通过Sigmoid函数整合到(0—1)之间。==
3 支持向量机|link
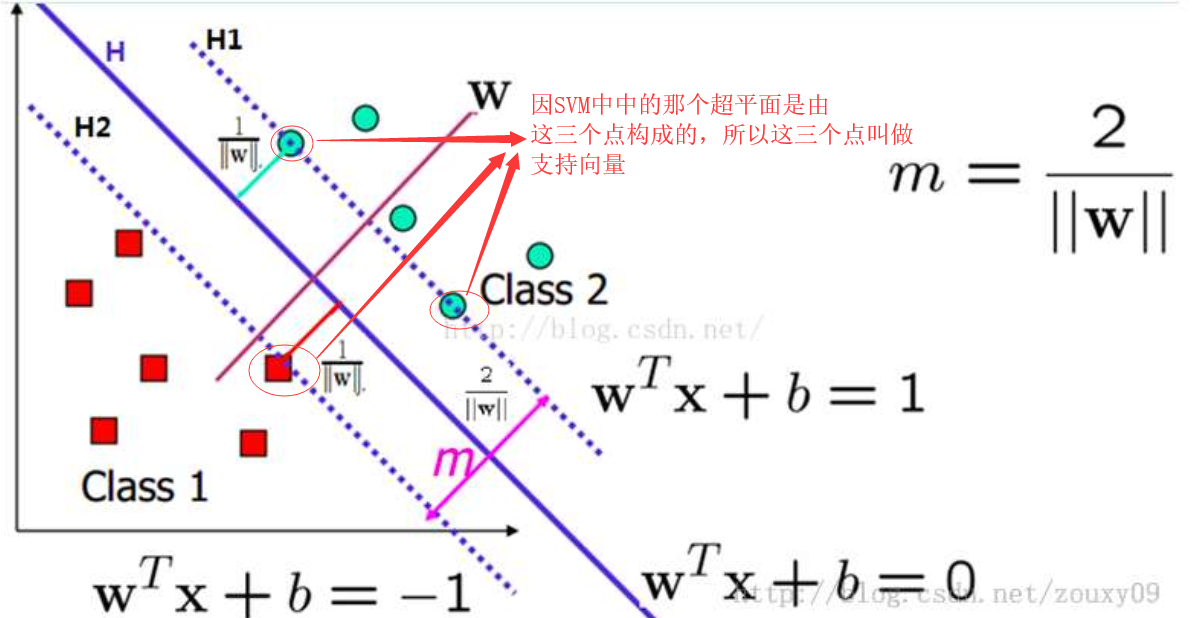
概念:SVM思想和线性回归很相似,两个都是寻找一条最佳直线。
不同点:最佳直线的定义方法不一样,线性回归要求的是直线到各个点的距离最近,SVM要求的是直线离两边的点距离尽量大。
4 随机森林算法|link
所以随机森林算法的随机性主要体现在以下两个方面:
- 子模型的训练样本是随机抽取的
- 子模型的特征变量也是随机抽取的
掌握随机森林之前,你学要具备如下知识:
随机森林的优缺点:| learn more
决策树算法的优缺点:
优点:
- (1)速度快: 计算量相对较小, 且容易转化成分类规则. 只要沿着树根向下一直走到叶, 沿途的分裂条件就能够唯一确定一条分类的谓词.
- (2)准确性高: 挖掘出来的分类规则准确性高, 便于理解, 决策树可以清晰的显示哪些字段比较重要, 即可以生成可以理解的规则.
- (3)可以处理连续和种类字段
- (4)不需要任何领域知识和参数假设
- (5)适合高维数据
缺点:
- (1)对于各类别样本数量不一致的数据, 信息增益偏向于那些更多数值的特征
- (2)容易过拟合
- (3)忽略属性之间的相关性
5 AdaBoost|link
6 贝叶斯网络|link
7 自编码网络|link
7.1 什么是自编码器?
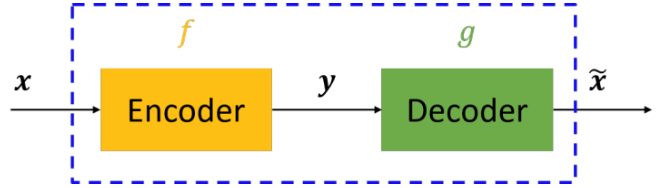
自编码器是一个3层或大于3层的神经网络,将输入表达式x编码为一个新的表达式y,然后再将y解码回x。这是一个非监督学习算法,使用反向传播算法来训练网络使输出等于输入。
图中,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。编码器将输入信号x变换成编码信号y,而解码器将编码y转换成输出信号x‘。即
y = f(x)x’ = g(y) = g(f(x))
自编码器的目的是,让输出x’尽可能复现输入x。
如果f和g都是恒等映射,那不就恒有x’=x?不错,但是这样的变换没啥作用。因此,我们对中间信号y做一定的约束,这样,系统往往能学出很有趣的编码变换f和编码y。
对于自编码器,我们需要强调一点是,我们往往并不关心输出是啥(反正只是复现输入),我们关心的是中间层的编码,或者说是从输入到编码的映射。
可以这么理解,我们在强迫编码y和输入x不同的情况下,系统还能复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以另一种形式表现。这就是特征提取,而且是主动学出来的。实际上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
7.2 什么自编码网络?
自编码网络是非监督学习领域的一种,可以自动从无标注的数据中学习特征,是一种以重构输入信息为目标的神经网络,它可以给出比原始数据更好的特征描述,具有较强的特征学习能力,在深度学习中常用自编码网络生成的特征来取代原始数据,已取得更好效果。
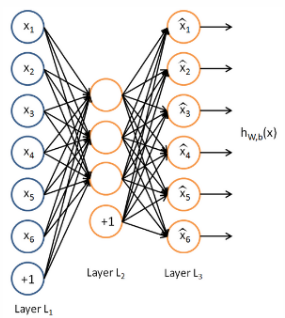
自编码器通过隐藏层对输入进行压缩,并在输出层中解压缩,整个过程肯定会丢失信息,但是通过训练我们能够使丢失的信息尽量减少,最大化的保留其主要特征。
y = f(x) = s(wx+b)
x’ = g(y) = s(w’y+b’)
L(x,x’) = L(x,g(f(x)))
其中L表示损失函数,结合数据的不同形式,可以是二次误差(squared error loss)或交叉熵误差(cross entropy loss)。
写在最后
欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
 wechat
wechat alipay
alipay bitcoin
bitcoin