一、Redis为什么这么快?
Redis是一个单线程应用,所说的单线程指的是Redis使用单个线程处理客户端的请求。
虽然Redis是单线程的应用,但是即便不通过部署多个Redis实例和集群的方式提升系统吞吐, 从官网给出的数据可以看出,Redis处理速度非常快。
Redis性能非常高的原因主要有以下几点:
- 内存存储:
Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销 - 单线程实现:
Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销 - 非阻塞IO:
Redis使用多路复用IO技术,在poll,epool,kqueue选择最优IO实现 - 优化的数据结构:
Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能
二、什么是IO多路复用技术
首先说一下,什么是IO多路复用技术。
比如,现在我们模拟一个tcp服务器处理30个客户的socket,如何快速的处理掉这30个请求呢?
在不了解原理的情况下,我们类比一个实例:在课堂上让全班30个人同时做作业,做完后老师检查,30个学生的作业都检查完成才能下课。如何在有限的资源下,以最快的速度下课呢?
- 第一种:安排一个老师,按顺序逐个检查。先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误。这种模式就好比,你用循环挨个处理
socket,根本不具有并发能力。这种方式只需要一个老师,但是耗时时间会比较长。 - 第二种:安排30个老师,每个老师检查一个学生的作业。 这种类似于为每一个
socket创建一个进程或者线程处理连接。这种方式需要30个老师(最消耗资源),但是速度最快。 - 第三种:安排一个老师,站在讲台上,谁解答完谁举手。这时C、D举手,表示他们作业做完了,老师下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。这种方式可以在最小的资源消耗的情况下,最快的处理完任务。
第三种就是IO复用模型(Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。)
三、5中IO模型
一个IO操作一般分为两个步骤:
- 等待数据从网络到达, 数据到达后加载到内核空间缓冲区
- 数据从内核空间缓冲区复制到用户空间缓冲区
按照两个步骤是否阻塞线程,分为阻塞/非阻塞, 同步/异步。
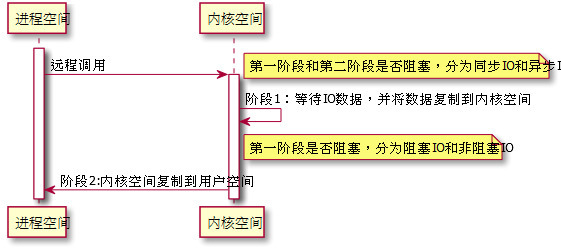
五种IO模型分类:
| 阻塞 | 非阻塞 | |
|---|---|---|
| 同步 | 阻塞IO | 非阻塞IO,IO多路复用,信号驱动IO |
| 异步IO | 异步IO |
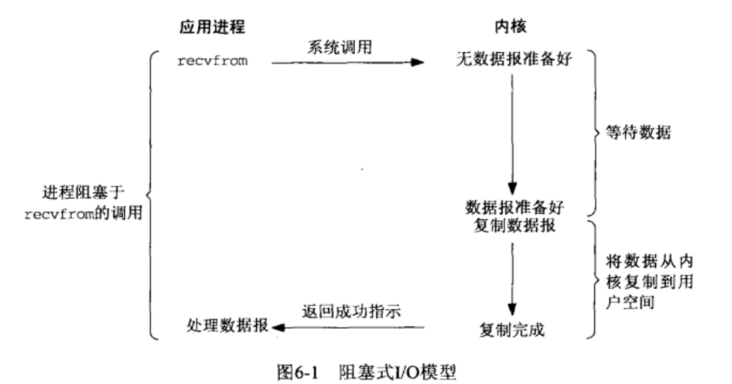
3.1 阻塞IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
3.2 非阻塞IO
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
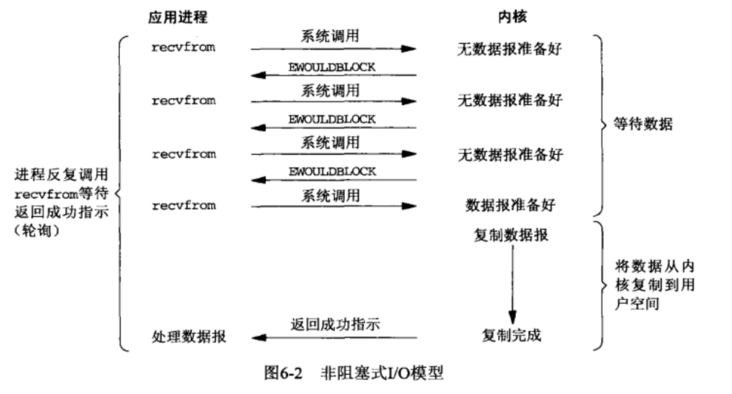
3.3 IO多路复用
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
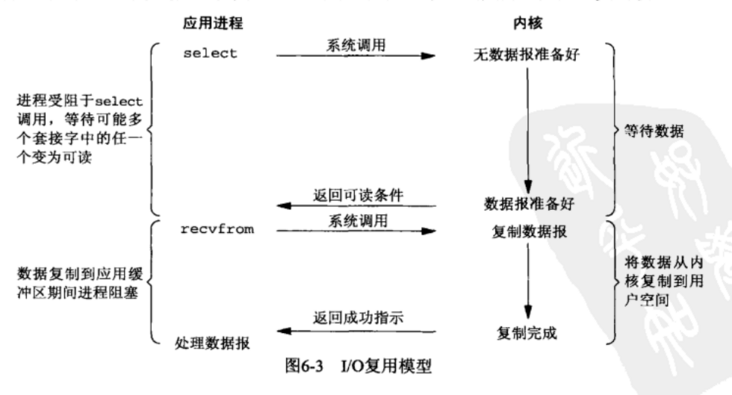
3.4 信号驱动IO
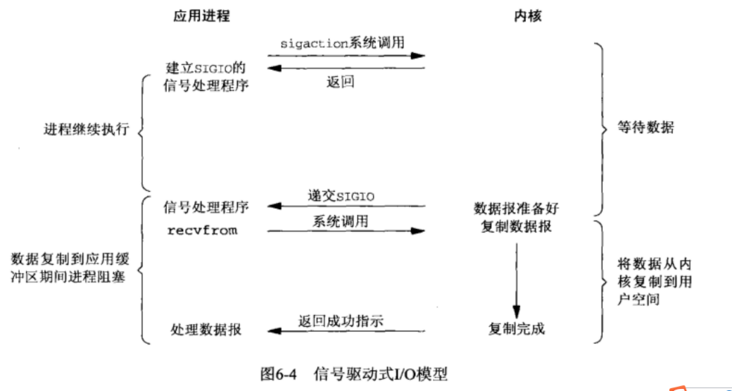
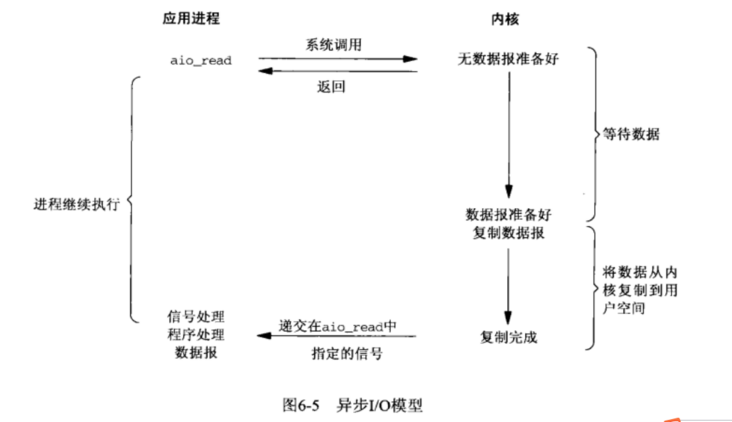
3.5 异步IO
Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入。先看一下它的流程:
四、Redis的IO处理
总的来说Redis使用一种封装多种(select,epoll, kqueue等)实现的Reactor设计模式多路复用IO处理客户端的请求。
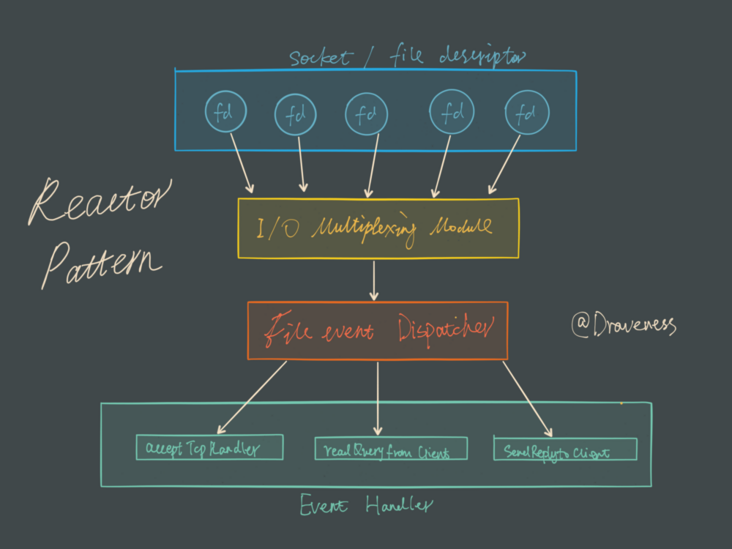
Reactor设计模式常常用来实现事件驱动。除此之外, Redis还封装了不同平台多路复用IO的不同的库。处理过程如下:
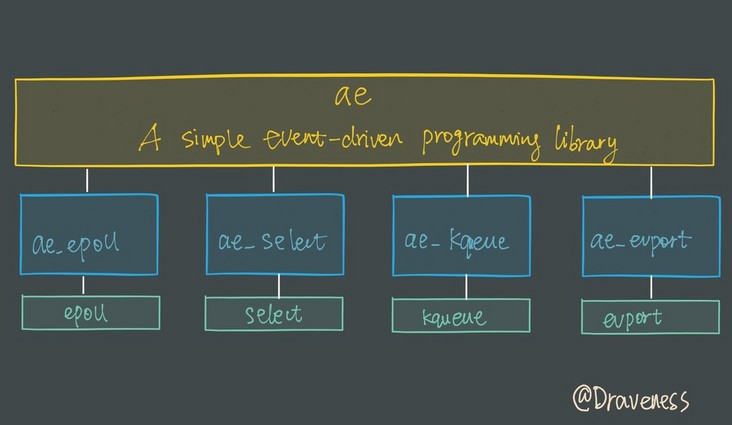
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块。
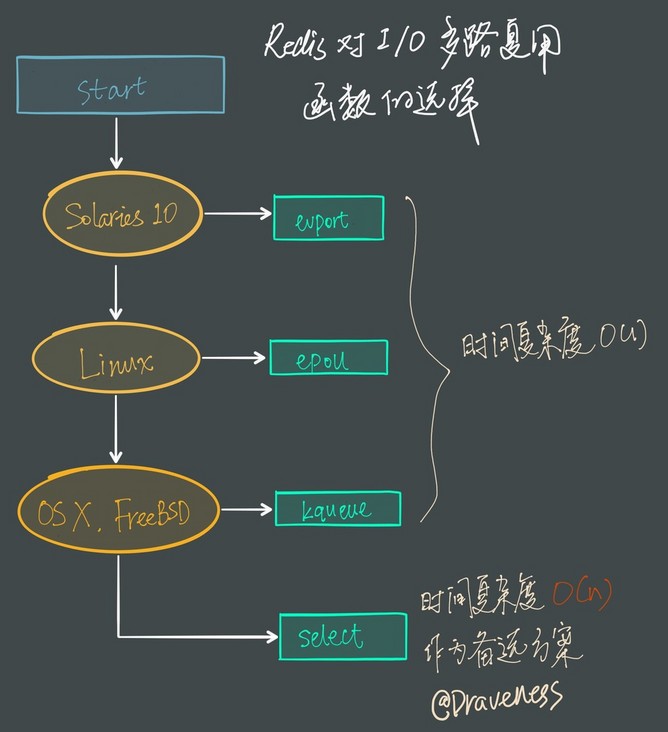
Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 O(n),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
Reference
- https://zhuanlan.zhihu.com/p/160157573
- https://segmentfault.com/a/1190000022088928
- https://github.com/littlejoyo/Blog/issues/6
写在最后
欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
 wechat
wechat alipay
alipay bitcoin
bitcoin