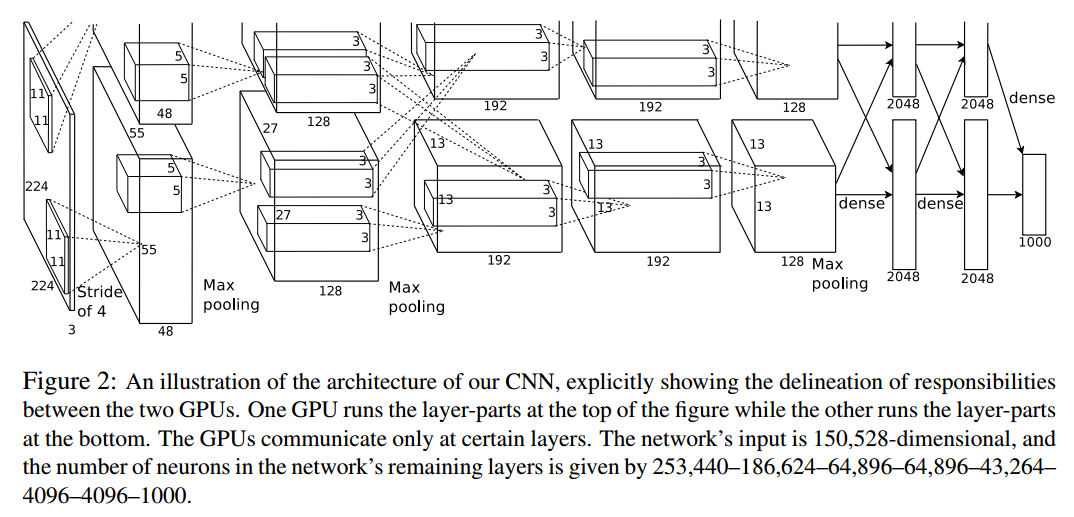
1 需要的环境配置
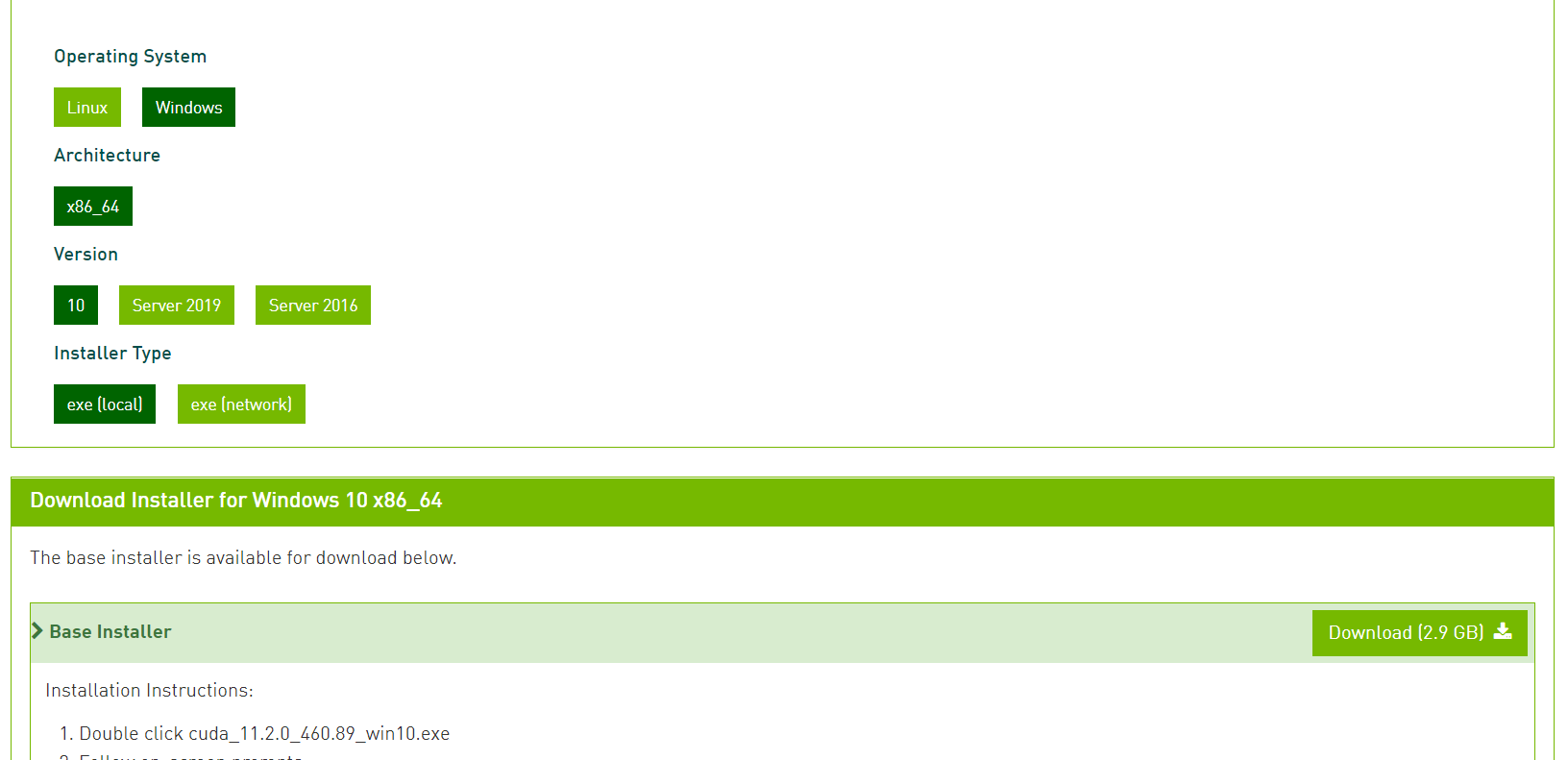
2 CUDA安装与配置 进入CUDA下载页面 选择对应的CUDA版本:
选择一个需要下载的版本,然后选择系统以及安装方式进行安装。
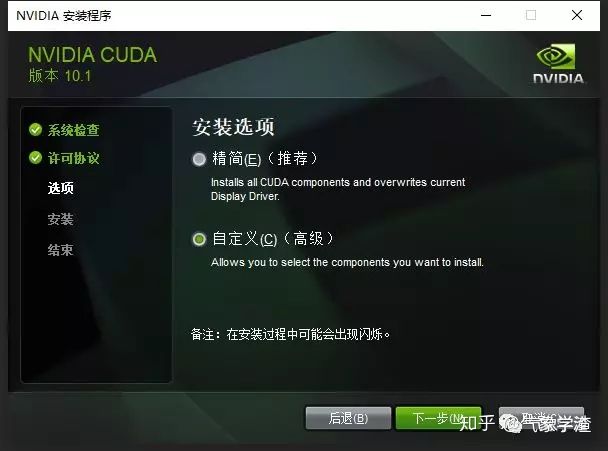
2.1 这里以本地安装(local)为例: 你可以选择精简安装和自定义安装:
精简安装:安装默认需要的包,这里不建议,因为可能有些包之前安装过,这里可能会覆盖之前安装的包、
自定义安装:自己选择一些需要安装的包,可以只安装自己需要的
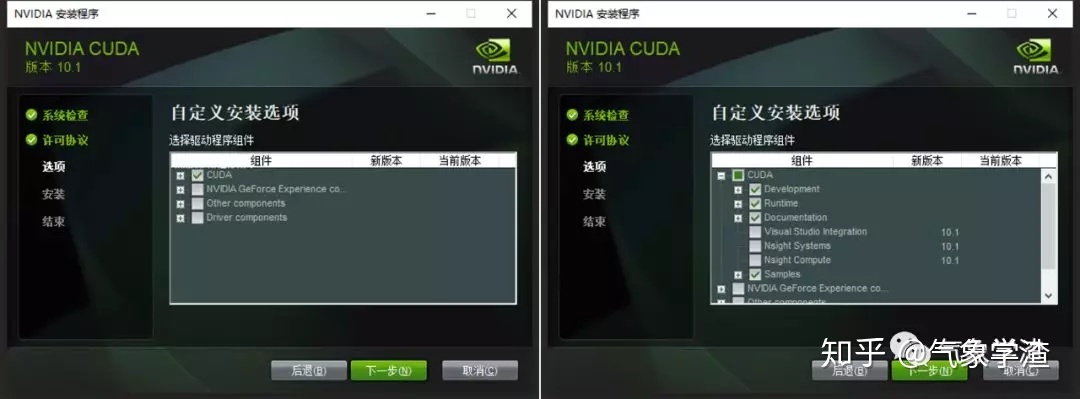
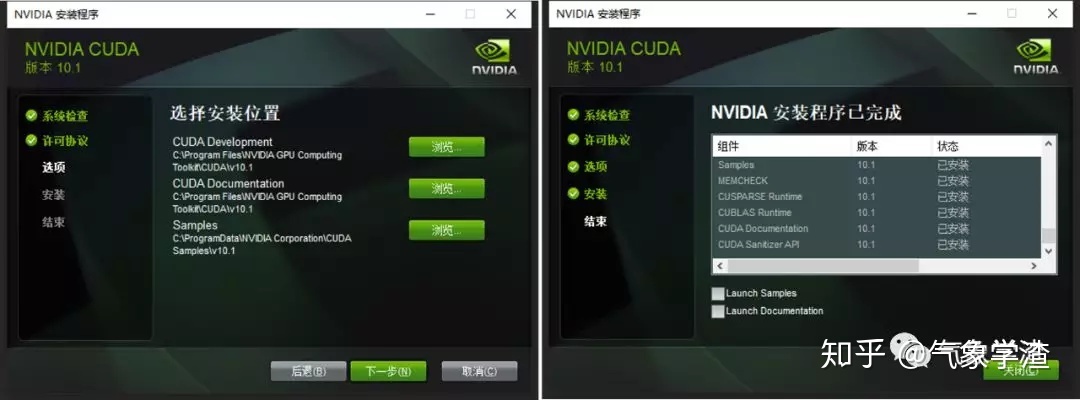
如图选择CUDA列表中的Development,Runtime,Documentation,Samples的四个组件,其他组件可按需安装:
记住安装位置,用来配置环境变量。
2.2 CUDA环境变量配置 点击【我的电脑】-》【属性】-》【高级系统设置】-》【环境变量】进行环境变量的配置,如果CUDA安装完成,默认会多出以下几个系统变量:CUDA_PATH、CUDA_PATH_V10_1、NVCUDASAMPLES_ROOT、NVCUDASAMPLES10_1_ROOT,下面式需要配置的:
1 2 3 4 5 CUDA_SDK_PATH:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1 CUDA_LIB_PATH:%CUDA_PATH%\lib\x64 CUDA_BIN_PATH:%CUDA_PATH%\bin CUDA_SDK_BIN_PATH:%CUDA_SDK_PATH%\bin\win64 CUDA_SDK_LIB_PATH:%CUDA_SDK_PATH%\common\lib\x64
1 2 3 4 5 6 7 8 %CUDA_LIB_PATH% %CUDA_BIN_PATH% %CUDA_SDK_LIB_PATH% %CUDA_SDK_BIN_PATH%; C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64 C:\ProgramFiles\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin C:\ProgramData\NVIDIACorporation\CUDA Samples\v10.1\common\lib\x64 C:\ProgramData\NVIDIACorporation\CUDA Samples\v10.1\bin\win64
3 安装和配置cuDNN 进入cuDNN官网 下载相应版本的cuDNN。cuDNN的全程为NVIDIA CUDA® Deep Neural Network library,是NVIDIA专门针对深度神经网络中的基础操作而设计基于GPU的加速库。
cuDNN是一个压缩包,解压之后如下:
将对应的文件复制到CUDA的安装目录下,默认是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0(这里版本号是你下载的版本号)
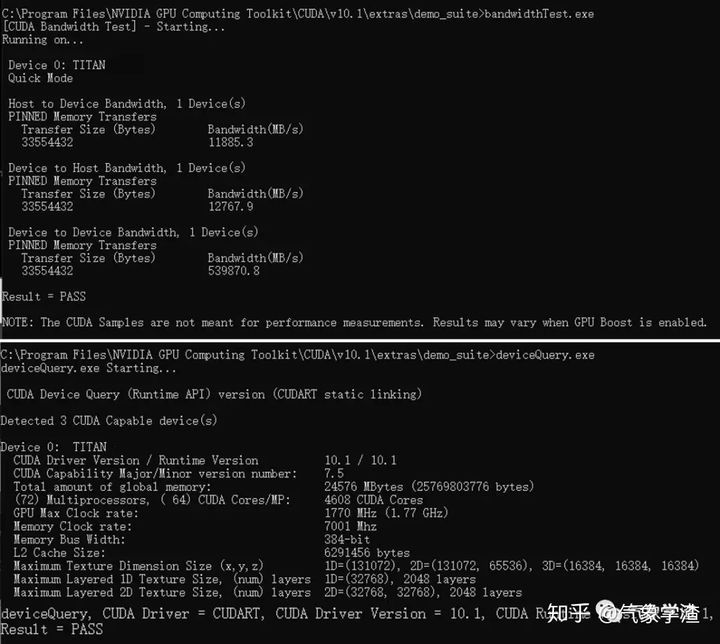
4 验证是否安装成功 安装之后,通过以下的方式进行验证,进入如下地址:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\extras\demo_suite,分别执行bandwidthTest.exe和deviceQuery.exe,若如图均返回PASS则说明配置生效。
5 创建tensorflow虚拟环境 anaconda安装这里略过,如果安装完anaconda之后,便可以继续操作。
使用如下命令创建虚拟环境:
1 conda create -name your_env_name python=version_no anaconda ##(如果末尾不添加anaconda命令,则该虚拟环境只有python,没有其他包)
其中your_env_name是你要创建的虚拟环境的名称,后面的version_no为你指定的python版本,如下:
创建完之后可以使用如下命令查看已经创建的虚拟环境:
1 2 conda info -e conda env list ## 两个命令都可以
创建完虚拟环境之后,然后激活该虚拟环境:
1 conda activate gpu ## gpu为我创建的虚拟环境
安装腾搜人flow-gpu:
1 conda install tensorflow-gpu
安装完之后:
使用如下命令查看是否安装成功:
1 2 3 4 import tensorflow as tfhello=tf.constant('hello!' ) sess=tf.Session() print (sess.run(hello))
6.1 测试tensorflow是否使用GPU计算 当运行上述代码时,如果输出如下信息,表示tensorflow在使用GPU进行计算。
1 2 3 4 5 6 7 8 9 10 11 2021-01-26 16:52:39.588750: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties: pciBusID: 0000:01:00.0 name: GeForce GTX 1660 Ti computeCapability: 7.5 coreClock: 1.59GHz coreCount: 24 deviceMemorySize: 6.00GiB deviceMemoryBandwidth: 268.26GiB/s 2021-01-26 16:52:39.589095: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll 2021-01-26 16:52:39.592145: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_10.dll 2021-01-26 16:52:39.595130: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cufft64_10.dll 2021-01-26 16:52:39.596242: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library curand64_10.dll 2021-01-26 16:52:39.599306: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusolver64_10.dll 2021-01-26 16:52:39.601463: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusparse64_10.dll 2021-01-26 16:52:39.609400: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll 2021-01-26 16:52:39.609656: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1697] Adding visible gpu devices: 0
6 测试GPU和CPU的速度 测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 ''' @author: crazy jums @time: 2021-01-24 20:55 @desc: 添加描述 ''' import osos.environ["CUDA_VISIBLE_DEVICES" ]="0" import numpy as npfrom tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flattenfrom tensorflow.keras.datasets import mnistfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.callbacks import TensorBoardimport timedef create_model (): model = Sequential() model.add(Conv2D(32 , (5 , 5 ), activation='relu' , input_shape=[28 , 28 , 1 ])) model.add(Conv2D(64 , (5 , 5 ), activation='relu' )) model.add(MaxPool2D(pool_size=(2 , 2 ))) model.add(Flatten()) model.add(Dropout(0.5 )) model.add(Dense(128 , activation='relu' )) model.add(Dropout(0.5 )) model.add(Dense(10 , activation='softmax' )) return model def compile_model (model ): model.compile (loss='categorical_crossentropy' , optimizer="adam" , metrics=['acc' ]) return model def train_model (model, x_train, y_train, batch_size=128 , epochs=10 ): tbCallBack = TensorBoard(log_dir="model" , histogram_freq=1 , write_grads=True ) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True , verbose=2 , validation_split=0.2 , callbacks=[tbCallBack]) return history, model if __name__ == "__main__" : import tensorflow as tf print (tf.__version__) from tensorflow.python.client import device_lib print (device_lib.list_local_devices()) (x_train, y_train), (x_test, y_test) = mnist.load_data() print (np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test)) x_train = np.expand_dims(x_train, axis=3 ) x_test = np.expand_dims(x_test, axis=3 ) y_train = to_categorical(y_train, num_classes=10 ) y_test = to_categorical(y_test, num_classes=10 ) print (np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test)) model = create_model() model = compile_model(model) print ("start training" ) ts = time.time() history, model = train_model(model, x_train, y_train, epochs=2 ) print ("start training" , time.time() - ts)
计算结果如下:
GPU计算10个epoch的时间:31.588526725769043秒 平均每个epoch15秒
CPU计算2个epoch的时间:104.25619554519653秒 平均每个epoch52秒
参考文章 https://zhuanlan.zhihu.com/p/83596098
写在最后 欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。




 wechat
wechat alipay
alipay bitcoin
bitcoin