美国区apple ID充值教程以及需要注意的一些问题
1 注册美区Apple ID2 给美区Apple ID充值美元前提准备:
一个机场,可以翻墙的机场
一个已经注册好的美区的Apple ID
一张双币信用卡,最好是美国运通(America Express)的,因为实测visa或者万事达的好像充值总是失败
给美区Apple ID充值美元的方式有是三种,分别为:购买美国gift card进行充值,绑定美国发行的信用卡(注意:这里只能是美国发行的信用卡,下面的Q&A会作详细解答)以及美国区的PayPal账号(这里也只能是美国的PayPal账号)。
2.1 通过购买gift card进行充值2.1.1 美国官网购买可以谷歌搜索gift card或者直接点击该链接跳转到gift card充值页面。
注意:这里需要特别注意,一定要在美国官网进行充值,在中国官网购买的充值卡只能在国区的Apple ID进行使用,且中国官网购买的充值卡充值之后,只能在APP Store进行消费,而美国区官网购买的充值卡充值之后不仅可以在APP Store进行消费,还可以在iTunes Store等苹果其他的商店进行消费,也就是说美国官网购买的充值卡的钱是通用 ...
0-1背包问题、完全背包、多重背包问题
1 0-1背包
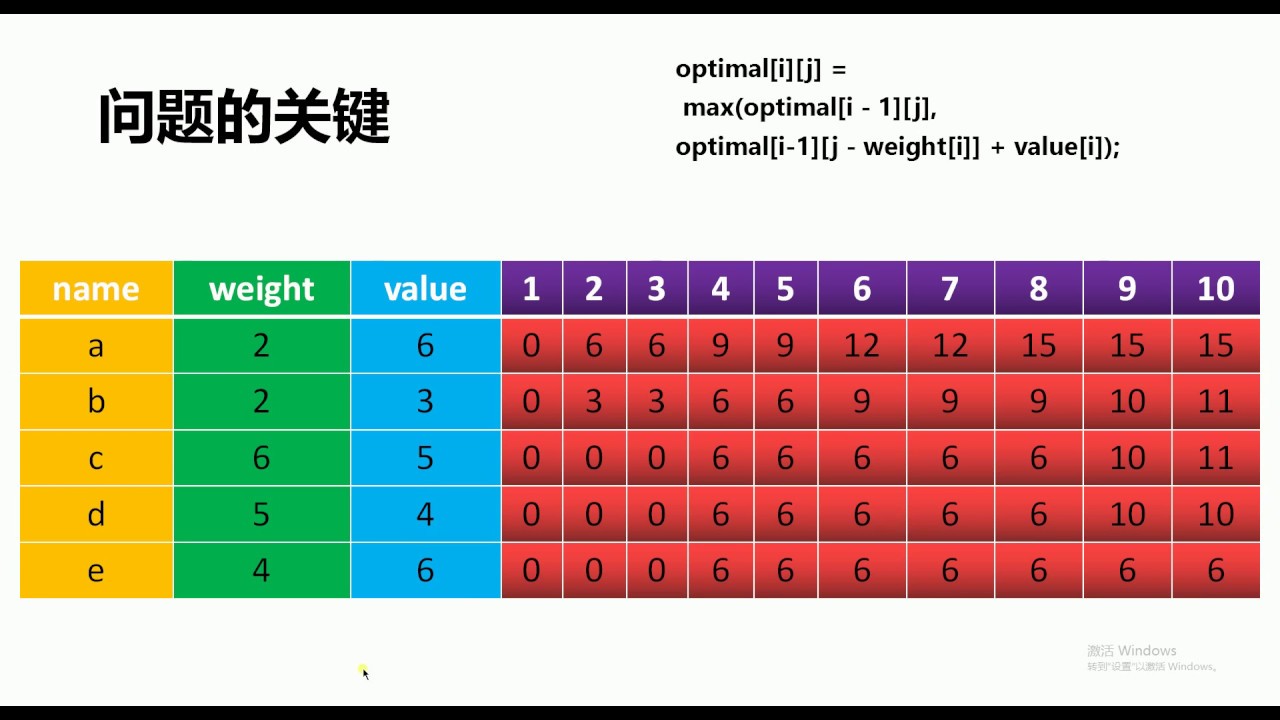
题目:有N件物品和一个容量为V的背包。第i建物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使价值总和最大(每件物品只能被使用一次)
根据题目,可以确定使用动态规划思路进行求解,定义一个数组$dp$,$dp[i][j]$表示有$i$件物品,背包容量是$j$所能装入的物品的最大价值。
则有状态转移方程如下:$dp[i][j]=max(dp[i-1][j],dp[i-1][j-c[i]]+w[i])$
其中,每次选取都有两种选择:
装入背包(背包能放得下该物品):则问题就转化成前$i-1$件物品装入容量为$j$的背包的最大价值,则表示为$dp[i-1][j-c[i]]$,再加上当前物品$i$的价值$w[i]$,
不装入背包:那么问题就转换成前$i-1$件物品放入容量为$j$的背包的最大价值,则$dp[i-1][j]$
1234567891011121314151617181920/**** @param n 物体的数量* @param w 背包所能放物体的最大重量* @param wt 每件物体的重量* @param val 每件物体的价值* ...
HashMap的HashTable区别?
1 二者区别
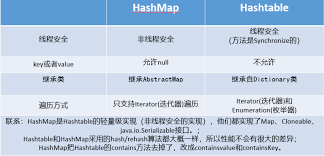
线程安全
HashMap是线程不安全的,如果多个线程同时访问某一个具体的HashMap实例时,需要提供相应的同步操作
HashTable是线程安全的(从下面的部分源码可以看出,HashTable的每个方法都是用了关键字synchronized进行修饰,也就是加了同步锁,而HashMap都没有),多个线程同时访问某个具体的实例不需要额外的同步操作,内部已经实现
是否运行为空
HashMap允许key=null和value=null
HashTable不允许
Hashtable 和 HashMap 采用的 hash/rehash 算法都大概一样,所以性能不会有很大的差异
继承关系
HashMap是Map接口的一个实现
HashTable是继承自Dictionary的一个子类
哈希方式
HashMap重新计算了key对象的哈希值
HashTable直接使用对象的hashCode值作为哈希值
初始大小和扩容方式
HashMap的初始大小为16,默认按照old*0.75的方式进行扩容,关键代码:
1234else { // zero ...

ArrayList和LinkedList的区别?
1 二者的区别
底层数据结构:
ArrayList底层是通过动态数组实现的
LinkedList底层是通过双向链表实现的
随机访问
ArrayList的随机访问get和set要优于LinkedList,因为LinkedList需要遍历移动指针
LinkedList的随机访问时间复杂度是$O(N)$,ArrayList的随机访问时间复杂度是$O(1)$
插入和删除操作
对于插入和删除操作而言,LinkedList并不比ArrayList快,因为LinkedList需要定位到某个插入或者删除的位置(index)也需要$O(N)$的时间复杂度,数据量越大,LinkedList较ArrayList的性能就越低(后面的测试用例可证明这一点)。
2 源码分析2.1 ArrayList中的随机访问、添加和删除部分源码如下:123456789101112131415161718192021222324252627282930313233343536373839404142434445//获取index位置的元素值public E get(int index) { rang ...
使用枚举创建单例对象
1 枚举的基本用法枚举可以有成员方法、成员属性和构造方法。定义一个枚举:
123enum eType{ A,B,C,D;//成员属性}
创建枚举时,$JVM$会自动创建一个继承自java.lang.Enum的类,上面的enum可以看做如下:
1234enum eType extends Enum{ public static final eType A; ...}
对于上面的枚举,可以看做是一个类,类名是eType,其中A、B、C、D可以看做eType的四个实例。但是该实例不需要手动创建,且枚举的构造方法时私有的,所有我们也不能够调用,只能有$JVM$进行调用。
由于A、B、C、D可以看做eType的四个实例,所以可以在enum中定义实例的变量和方法:
1234567891011enum eType{ A,B,C,D; //成员属性 static int value; //静态变量 public static int getValue() { //静态方法 return v ...
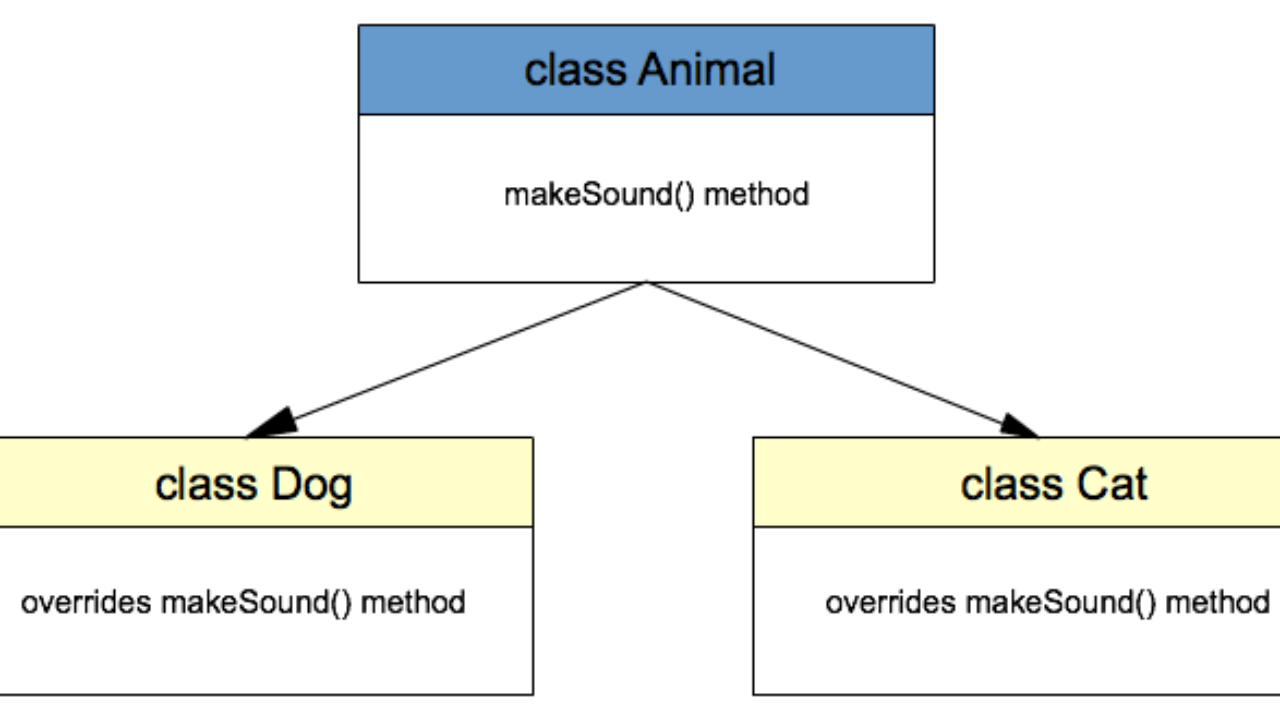
java多态总结
1.定义多态:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
2.实现多态的技术称为动态绑定(dynamicbinding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
3.作用消除类型之间的耦合关系。
4.现实中,关于多态的例子不胜枚举比方说按下F1键这个动作,如果当前在Flash界面下弹出的就是AS3的帮助文档;如果当前在Word下弹出的就是Word帮助;在Windows下弹出的就是Windows帮助和支持。同一个事件发生在不同的对象上会产生不同的结果。
5.多态存在的三个必要条件
要有继承;
要有重写;
父类引用指向子类对象。
6.多态的好处:
可替换性(substitutability):多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。
可扩充性(extensibility):多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如 ...
java多态面试题
多态分两种:
(1) 编译时多态(设计时多态):方法重载。
(2) 运行时多态:JAVA运行时系统根据调用该方法的实例的类型来决定选择调用哪个方法则被称为运行时多态。(我们平时说得多的事运行时多态,所以多态主要也是指运行时多态)
运行时多态存在的三个必要条件:
要有继承(包括接口的实现);
要有重写;
父类引用指向子类对象。
多态的好处:
可替换性(substitutability)。多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。
可扩充性(extensibility)。多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如,在实现了圆锥、半圆锥以及半球体的多态基础上,很容易增添球体类的多态性。
接口性(interface-ability)。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的。如图8.3 所示。图中超类Shape规定了两个实现多态的接口方法,computeArea()以及computeV ...
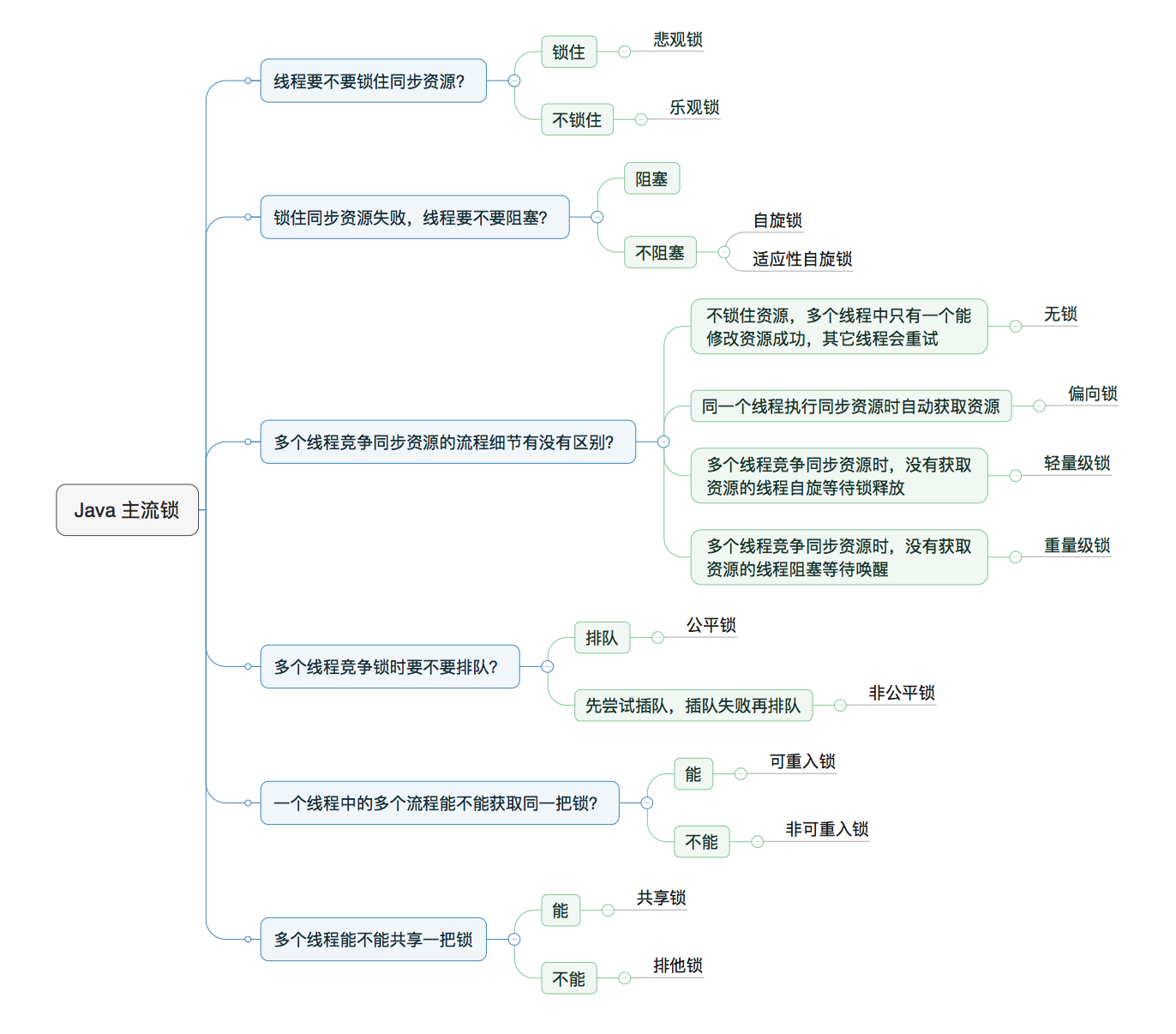
java多线程中的锁机制
reference
Java提供了种类丰富的锁,每种锁因其特性的不同,在适当的场景下能够展现出非常高的效率。本文旨在对锁相关源码(本文中的源码来自JDK 8和Netty 3.10.6)、使用场景进行举例,为读者介绍主流锁的知识点,以及不同的锁的适用场景。
Java中往往是按照是否含有某一特性来定义锁,我们通过特性将锁进行分组归类,再使用对比的方式进行介绍,帮助大家更快捷的理解相关知识。下面给出本文内容的总体分类目录:
1. 乐观锁 VS 悲观锁乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。
先说概念。对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java中,synchronized关键字和Lock的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新, ...
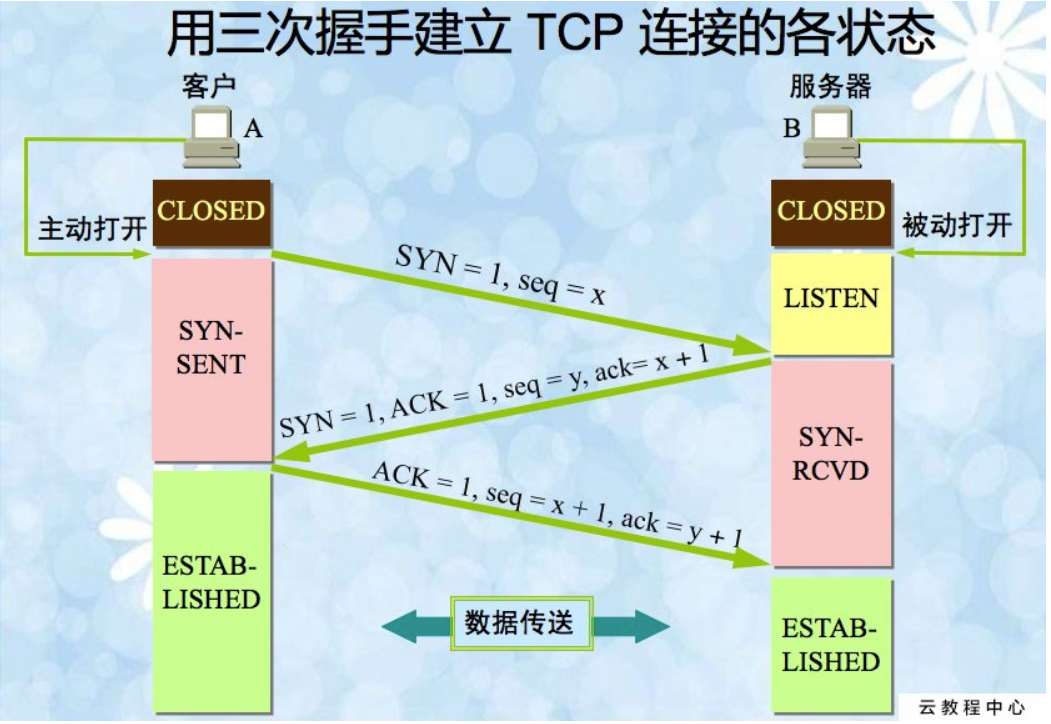
TCP/IP协议的三次握手为什么是三次而不是两次?
简单来说,三次握手的目的是为了让双方验证各自的接收能力和发送能力。
第一次握手,A 发送SYN到B,B接收到了后,能确认什么呢?
显然,B能确认A的发送能力和B的接收能力;
第二次握手,B发送SYNACK到A,A接收到后,能确认什么呢?
A能确认B的发送能力和A自己的接收能力,此外,A收到了SYNACK,那么说明前面A发的SYN成功到达B的手中,所以也能确认A自己的发送能力和B的接收能力;至此,A已经确认了双方各自的发送能力和接收能力都是OK的,因此转为ESTABLISHED状态;
第三次握手,A发送ACK到B,B接收后,能确认什么呢?
直接的,B能确认A的发送能力和B的接收能力,另外由于B能收到ACK说明前面发送的SYNACK已经成功被接受了,说明能确认A的接收能力和B的发送能力。
如果使用两次握手,就不能确认上述所说的四种能力,那么就会导致问题。
假定不采用第三次报文握手,那么只要B发出确认,新的连接就建立了。
现假定一种异常情况,即A发出的SYN报文段并没有丢失,而是在某些网络节点长时间滞留了,以致延误到连接释放后的某个时间才到达B。本来这是一个早已失效 ...
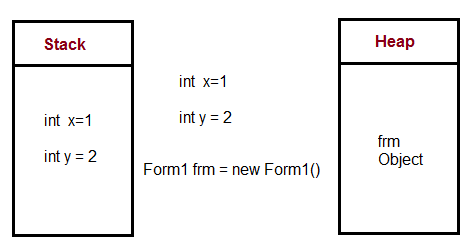
Diffience between Stack and Heap Memery in java ?
reference
Sr. No.
Key
Stack
Heap Memory
1
Basic
Stack memory is used to store items which have a very short life like local variables, a reference variable of objects
Heap memory is allocated to store objects and JRE classes.
2
Ordering
The stack is always reserved in a LIFO (last in first out) order
Heap memory is dynamic allocation there is no fixed pattern for allocating and deallocating blocks in memory
3
Size
We can increase stack memory size by using JVM parameter -XSS
We can inc ...