消息队列的使用场景:异步、削峰(负载均衡)、解耦。
1 异步(提升系统相应速度)
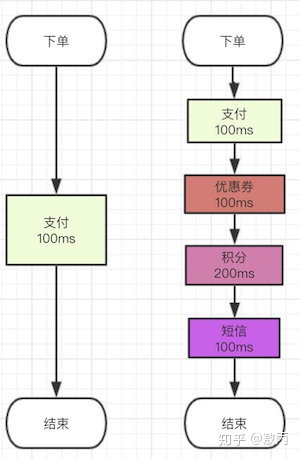
场景一:当电商购物的过程中,需要付款,那么付款就是一个简单的流程,假如说需要花费$100ms$。由于现在都是基于微服务开发的应用,那么每添加一个新的功能,就相应会多一个新的微服务系统,各个微服务系统之间的通信协作就会花费较多时间。那么当后期需要添加新功能时,可能会添加**优惠券系统($100ms$)、积分系统($100ms$)**等。可能一次付款成功的操作会有十几个相应的非主流业务也要执行,如果使用同步的方式那么会消耗很长的时间,所以这个时候使用消息中间件来进行异步执行各个非主流的业务。这样整个下单过程就会值消耗$100ms$的时间,而所有的非主流业务都执行了。
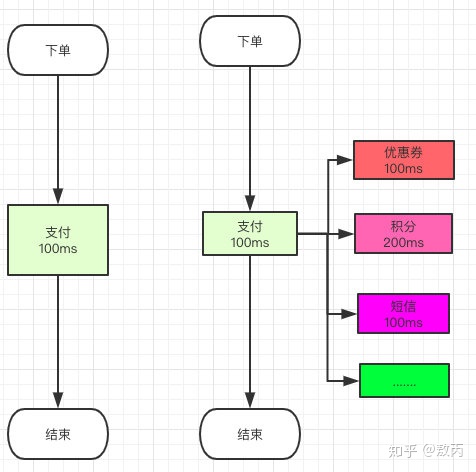
2 削峰(负载均衡,抵抗请求高峰时期)
假如某个服务器只能承受5000的访问量,那么当此时有8000的访问量时,那么当前的服务器一定会宕机,如果使用消息中间件,将所有的请求流量添加到消息中间件中,此时由服务器去消息中间件中取请求的事件,此时服务器可以根据当前的总请求数进行协调与均衡,不至于让服务器宕机。比如淘宝双十一凌晨12点时,此时流量会瞬间暴涨,但是淘宝的服务并没有挂掉,但是后有卡顿,等高峰过去之后,系统又可以恢复正常的运行。
3 解耦(降低系统耦合度)
正如之前所说,在订单付款时,可能伴随着很多的非主流业务的发生,但是这些业务之间应该解耦的,也就说各个业务之间的运行不能相互影响,当订单支付成功之后,将其支付成功的消息放到消息队列中, 各个非主流业务只要去监听消息队列中的支付成功的消息就可以了,如果监听到就执行相应的操作,就实现了各个功能的解耦。
4 消息中间件的问题?
重复消息(幂等性)
首先你的明白重复消费会出现什么问题,为什么要保证幂等性。举个例子: 如果消费者干的事儿是拿一条数据就往数据库里写一条,你可能就把数据在数据库里插入了 2 次, 那么数据就错了。其实重复消费不可怕, 可怕的是你没考虑到重复消费之后,怎么保证幂等性。 解决: 每个消息加一个全局唯一的序号,根据序号判断这条消息是否处理过, 然后再根据自己的业务场景进行处理。或更新或丢弃。
消息丢失
消息生产者把消息搞丢了: RabbitMQ开启 confirm 模式,如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息, 告诉你说这个消息 ok 了。 如果 RabbitMQ 没能处理这个消息,会回调你的一个 nack 接口,告诉你这个消息接收失败,你可以重试。 而且你可以结合这个机制自己在内存里维护每个消息id的状态, 如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
MQ自己搞丢了数据: RabbitMQ可以开启持久化
消费端丢失了数据: RabbitMQ默认是自动ack的,也就是说消息到了消费端,就会自动确认已经消费了这条消息, 这时候可能你消费端刚拿到数据,然后挂了,那这条消息不就丢失了。 关闭RabbitMQ的自动确认,每次消费端逻辑处理完的时候, 在程序里确认消费完成,通知MQ,这样就保证了在消费端不会丢失了
顺序消费
RabbitMQ: 拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点; 或者就一个 queue 但是对应一个 consumer
Kafka: 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低, 一般不会用这个。 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程, 每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
系统复杂性
- 使得原本的系统变得复杂,维护成本增加
数据一致性:
- 可以使用分布式事务解决该问题
可用性:如果中间件挂了怎么办
- 磁盘缓存,持久化
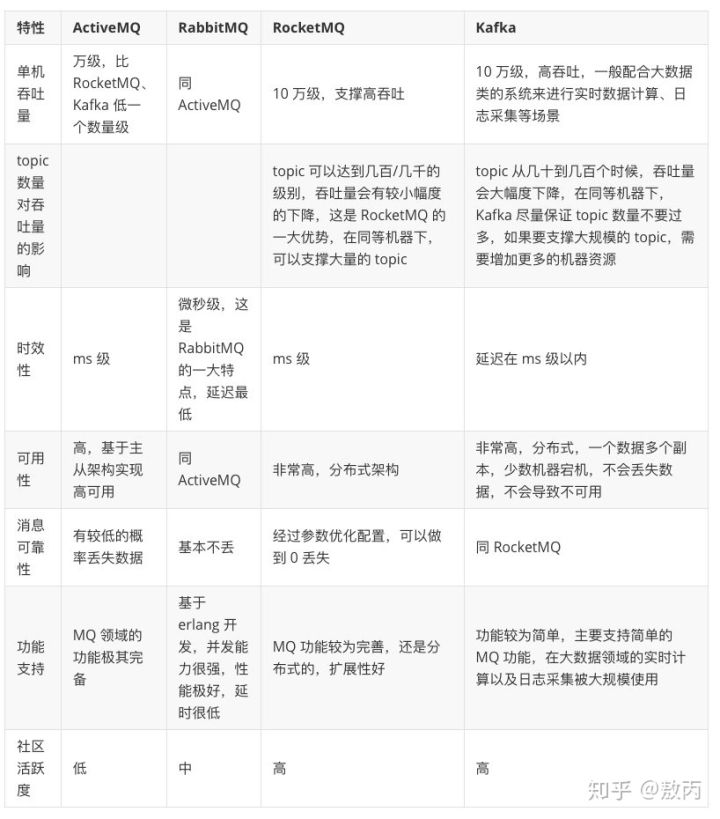
5 不同消息中间件的对比、
Kafka和RocketMQ一直在各自擅长的领域发光发亮,不过写这篇文章的时候我问了蚂蚁金服,字节跳动和美团的朋友,好像大家用的都有点不一样,应该都是各自的中间件,可能做过修改,也可能是自研的,大多没有开源。
写在最后
欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
 wechat
wechat alipay
alipay bitcoin
bitcoin