如何让自己的hexo博客被Google和百度收录
推荐阅读关于如何让自己的hexo博客能够让百度或者谷歌收录,可以查看下面这篇博客。
如何让自己的hexo博客被Google和百度收录
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。

用Python扫描文件夹中所有文件,并将部分文件按要求改名字
话不多说,直接上代码1234567891011121314151617import osimport redef scan_files(directory, prefix=None, postfix=None): count = 0 for files in os.walk(directory): for file in files[2]: if "微信截图_" in file: count += 1 newname = re.sub("微信截图_","",file) os.rename(directory+file,directory+newname) break print("改名完成,一共改名{}个文件".format(count))if __name__ == '__main__': dir = r ...

查看hexo已经安装的三方包命令
查看命令1npm list --depth 0
命令解释:
–depth 查看已经三方的深度,默认是显示所有,用0只显示最外层
显示结果下所示:
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
hexo个人博客绑定个人域名
1 注册个人域名进入到腾讯云平台,自己注册一个账号(微信登录即可),下面是网址:https://cloud.tencent.com/act/domainsales?from=dnspodqcloud
2 开始域名解析自己按照步骤购买域名,第一年是1元,然后进入到控制台,进入域名解析界面,如下:点击【解析】进入到域名解析界面,如下:
3 创建CNAME文件创建一个CNAME文件:
这几个字母必须是大写
没有后缀名
用记事本打开将自己的域名写在里面,如:
4 部署到GitHub将CNAME文件放到publics文件夹里面,然后上传到GitHub,命令如下:
1hexo d
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。

tensorflow如何控制输出控制台的日志等级
123456789import os# 输出所有 默认等级os.environ["TF_CPP_MIN_LOG_LEVEL"]='1'# 输出warm和erroros.environ["TF_CPP_MIN_LOG_LEVEL"]='2'# 只输出erroros.environ["TF_CPP_MIN_LOG_LEVEL"]='3'
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
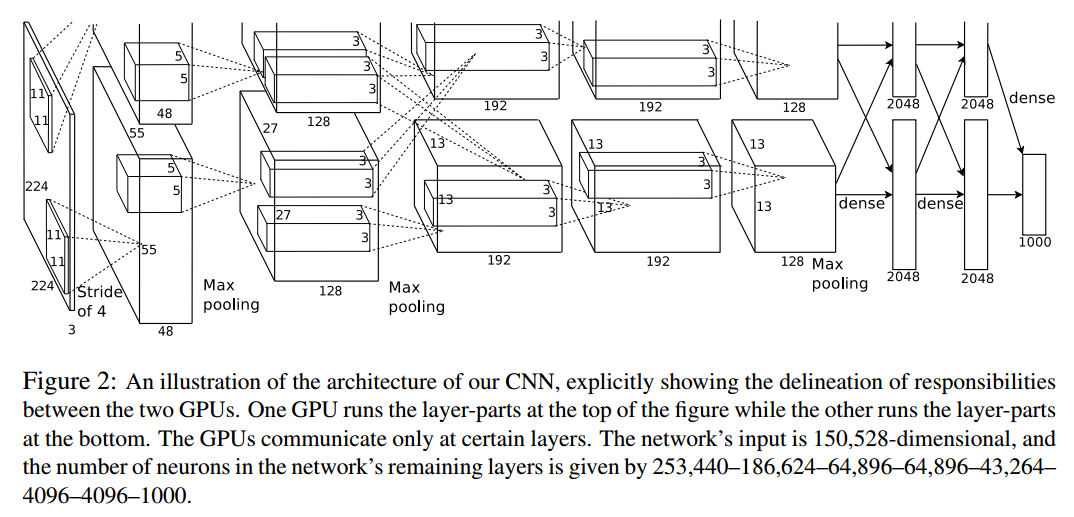
CNN典型模型:AlexNet
论文出处:《ImageNet Classification with Deep Convolutional Neural Networks》一篇很好的理解AlexNet模型的博客AlexNet 的网络结构如下所示:
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
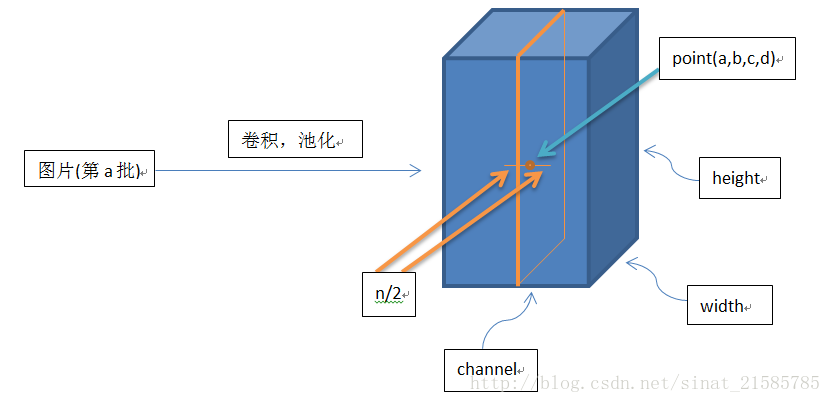
关于局部响应归一化层(LRN),了解一下
局部响应归一化层(Local Response Normalization)本篇博客参考自:https://www.jianshu.com/p/c014f81242e7
局部响应归一化层简称LRN,是在深度学习中提高准确度的技术方法。一般是在激活、池化后进行的一种处理方法,因在Alexnet中运用到,故做一下整理。
为什么要引入LRN层?首先要引入一个神经生物学的概念:侧抑制(lateral inhibitio),即指被激活的神经元抑制相邻的神经元。归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用RELU的时候,这种“侧抑制”很有效 ,因而在alexnet里使用有较好的效果。
归一化有什么好处?1.归一化有助于快速收敛;2.对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。【补充:神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降 ...

深度学习和机器学习的区别?
关于深度学习和机器学习,他们有如下几点不同之处:
1 特征提取方面
机器学习必须通过人工特征提取之后,才能进行后续的识别等操作
深度学习则不同,深度学习深刻网络框架可以不需要人工进行特征提取,而是通过网络自动进行提取,那么深度学习就显得更加强大了
2 数据量和计算性能方面
算法代表机器学习:
素朴贝叶斯
决策树…
深度学习
神经网络
写在最后欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
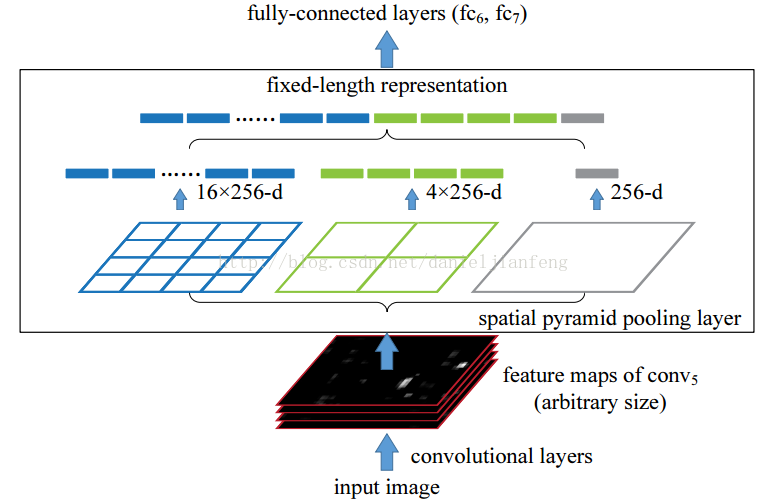
关于SSPNet(空间金字塔池化网络),了解一下
1 SSPNet论文出处SSPNet(Spatial Pyramid Pooling Network),中文名字是空间金字塔池化网络SSPNet论文出自《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》一篇较好的解读SSPNet的博客
1.1 为什么会提出SSPNetSSPNet的中文名称是空间金字塔池化网络,SSPNet的提出,是为了解决R-CNN遇到的一个拼劲问题,也就是R-CNN在候选区提取时,每张图片都需要经过一次CNN,运行速度很慢。如果你有2000张图片的话,那么你需要经过2000次CNN网络,这样的计算速度是非常慢的。 在了解SSPNet之前,让我们先了解一下R-CNN的工作原理,才能对其进行改进。
SSPNet完美解决上述R-CNN遗留的两个问题:
R-CNN在生成了候选区域后,需要对每个区域进行统一尺寸的压缩或放大,当候选集的长与宽差别较大时强行压缩至比例为1:1时会使图像产生变形和丢失图像的原始特征
R-CNN生成了多个候选集后需要全部输入到CN ...
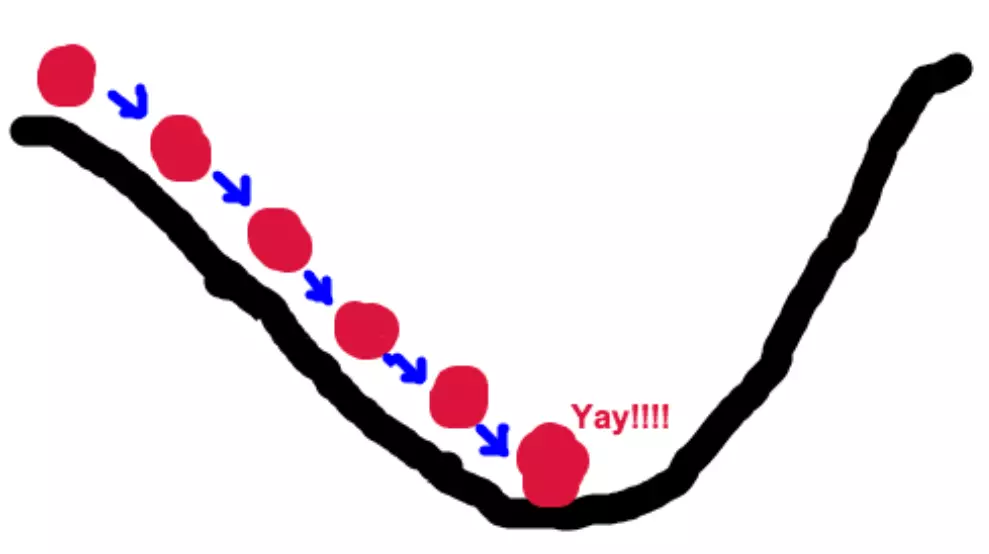
关于深度学习中的梯度下降,了解一下
一篇让你很容易理解什么是梯度下降的博客
0 什么是梯度下降
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。我们同时可以假设这座山最陡峭的地方是无法通过肉眼立马观察出来的,而是需要一个复杂的工具来测量,同时,这个人此时正好拥有测量出最陡峭方向的能力。所以,此人每走一段距离,都需要一段时间来测量所在位置最陡峭的方向,这是比较耗时的。那么为了在太阳下山之前到达山底,就要尽可能的减少测量方向的次数。这是一个两难的选择,如果测量的频繁,可以保证下山的方向是绝对正确的,但又非常耗时,如果测量的过少,又有偏离轨道的 ...