C++中栈和堆的区别?
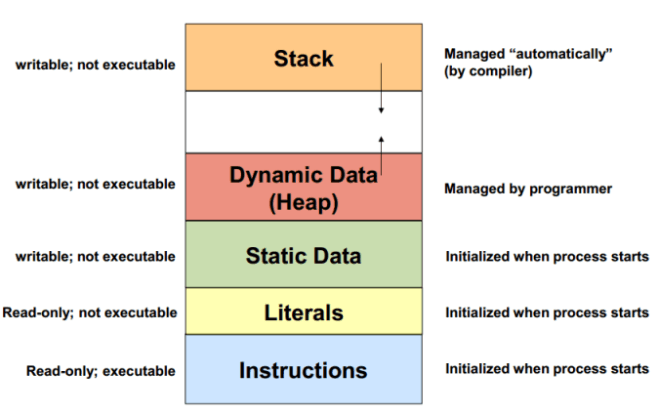
在计算机领域,堆栈是一个不容忽视的概念,我们编写的 C 语言程序基本上都要用到。但对于很多的初学着来说,堆栈是一个很模糊的概念。堆栈:一种数据结构、一个在程序运行时用于存放的地方,这可能是很多初学者的认识,因为我曾经就是这么想的和汇编语言中的堆栈一词混为一谈。我身边的一些编程的朋友以及在网上看帖遇到的朋友中有好多也说不清堆栈,所以我想有必要给大家分享一下我对堆栈的看法,有说的不对的地方请朋友们不吝赐教,这对于大家学习会有很大帮助。
1 数据结构的栈和堆首先在数据结构上要知道堆栈,尽管我们这么称呼它,但实际上堆栈是两种数据结构:堆和栈。堆和栈都是一种数据项按序排列的数据结构。
2 栈就像装数据的桶或箱子我们先从大家比较熟悉的栈说起吧,它是一种具有后进先出性质的数据结构,也就是说后存放的先取,先存放的后取。这就如同我们要取出放在箱子里面底下的东西(放入的比较早的物体),我们首先要移开压在它上面的物体(放入的比较晚的物体)。
3 堆像一棵倒过来的树而堆就不同了,堆是一种经过排序的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根 ...

tcp和udp有什么区别?面试题。
1 UDP和TCP的区别
如果是两台主机用UDP协议发送数据,那么他们在任意时刻都可以向对方发送数据,因为UDP是无连接的协议,而如果使用TCP协议进行通信,那么两台主机在通信之前需要进行三次握手建立连接,断开连接时需要进行四次挥手断开连接,TCP协议是面向连接的。(注意:这里所说的连接是指逻辑连接,而不是只物理连接。)
UDP支持单播、多播、广播通信,而TCP只支持单播通信。
UDP是面向应用报文的协议,TCP是面向字节流的协议
也就是说发送方使用UDP协议发送数据时会给该数据报文添加一个UDP头部,接收方接收到该数据报文后去掉其UDP头部直接交给应用进程,中间不做任何操作。
应用进程将需要发送的数据交给下面的TCP协议(传输层),需要发送的数据会首先放在TCP缓存中,TCP协议会根据一定的策略从TCP缓存中提取一定数量的字节并加上TCP头部发送给接收方,接收方收到数据后提取并去掉TCP头部先存放在TCP缓存中,然后将一部分数据交给应用进程。(TCP协议不能保证发送的每个字节都是有意义的,这个需要应用进程进行解析成有意义的字段。)
TCP和UDP都是全双工协议, ...
TCP/IP协议中的拥塞控制面试题
1 TCP拥塞控制
别看放在最后,因为是压轴的知识点,很重要!
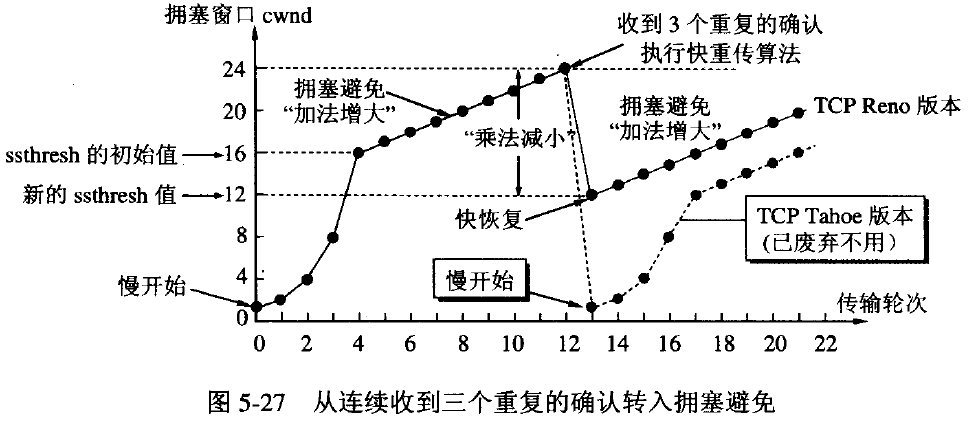
1.1 慢启动和拥塞避免(1)慢启动慢启动指先把拥塞窗口cwnd设置为一个最大报文段MSS的数值,发送方在每收到一个对新的报文段的确认后,把拥塞窗口增加至多一个MSS的数值,在每经过一个往返时间RTT,拥塞窗口wcnd就加倍。
慢启动的“慢”并不是指cwnd的增长速度慢,而是指在TCP开始发送报文段时先设置cwnd=1,使得发送方在开始时只发送一个报文段(目的是探测一下网络的拥塞情况)
(2)拥塞避免算法让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。
(3)步骤
当cwnd < ssthresh时,使用上述的慢启动算法;
当cwnd > ssthresh时,停止使用慢启动算法而改用拥塞避免算法;
当cwnd = ssthresh时,即可使用慢启动算法,也可以使用拥塞避免算法;
1.2 快速重传和快速恢复
当发送方向接收方发送数据时,中间可能会有个别数据包丢失,但是这不是网络拥塞,如果使用上面的慢启动+拥塞避免算法的话, ...

http和https协议的区别?
1 $HTTP$和$HTTPS$的区别?
reference
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
一、HTTP和HTTPS的基本概念HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种 ...
c++中指针和引用的区别?
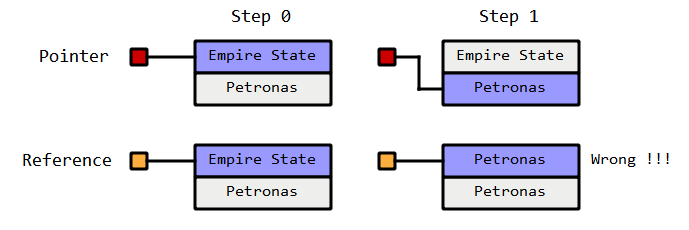
1 引用基础教程我们知道,参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 char、bool、int、float 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组、结构体、对象是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行频繁的内存拷贝可能会消耗很多时间,拖慢程序的执行效率。
C/C++ 禁止在函数调用时直接传递数组的内容,而是强制传递数组指针,这点已在《C语言指针变量作为函数参数》中进行了讲解。而对于结构体和对象没有这种限制,调用函数时既可以传递指针,也可以直接传递内容;为了提高效率,我曾建议传递指针,这样做在大部分情况下并没有什么不妥,读者可以点击《C语言结构体指针》进行回顾。
但是在 C++ 中,我们有了一种比指针更加便捷的传递聚合类型数据的方式,那就是引用(Reference)。
在 C/C++ 中,我们将 char、int、float 等由语言本身支持的类型称为基本类型,将数组、结构体、类(对象)等由基本类型组合而 ...

C++ class和struct到底有什么区别
C++ 中保留了C语言的 struct 关键字,并且加以扩充。在C语言中,struct 只能包含成员变量,不能包含成员函数。而在C++中,struct 类似于 class,既可以包含成员变量,又可以包含成员函数。
C++中的 struct 和 class 基本是通用的,唯有几个细节不同:
使用 class 时,类中的成员默认都是 private 属性的;而使用 struct 时,结构体中的成员默认都是 public 属性的。
class 继承默认是 private 继承,而 struct 继承默认是 public 继承(《C++继承与派生》一章会讲解继承)。
class 可以使用模板,而 struct 不能(《模板、字符串和异常》一章会讲解模板)。
C++ 没有抛弃C语言中的 struct 关键字,其意义就在于给C语言程序开发人员有一个归属感,并且能让C++编译器兼容以前用C语言开发出来的项目。
在编写C++代码时,我强烈建议使用 class 来定义类,而使用 struct 来定义结构体,这样做语义更加明确。
使用 struct 来定义类的一个反面教材:
1234567891011 ...

c++中,为什么有了malloc/free,还要new/delete?
malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。
由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
不要企图用malloc/free来完成动态对象的内存管理,应该用new/delete。由于内部数据类型的“对象”没有构造与析构的过程,对它们而言malloc/free和new/delete是等价的。
既然new/delete的功能完全覆盖了malloc/free,为什么C++不把malloc/free淘汰出局呢?这是因为C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
如果用f ...

steam下载在国内下载游戏很慢,解决办法
参考
1 解决办法
原因:steam下载速度慢是因为当前网络与下载服务器之间出现了波动,一般情况下修改下载节点即可解决问题,但是有些非中国区的游戏,就必须通过修改hosts文件来提高下载速度。
如果我们游戏下载速度慢,那么大多数是因为你所在的地方节点出现问题,我们可以进入设置菜单进行设置;首先我们打开设置,然后选择下载。
我们在下载时区中选择以北京节点,一般国内的游戏最好还是选择北京、成都,如果我们下载国外的游戏,可以选择日本或者韩国的节点进行下载;
那么我们更换节点依然无法解决问题怎么办呢?我们打开系统菜单,输入(用管理员打开)CMD呼出命令符,然后在命令符中输入:
1notepad "%systemroot%/system32/drivers/etc/hosts"
打开hosts文件后,我们在hosts文件中,输入以下内容:
161.147.228.241 cdn.mileweb.cs.steampowered.com.8686c.com
然后进行保存。
这时我们重启steam,然后继续下载游戏,你会发现游戏的下载速度已经达到了峰值,这样就 ...
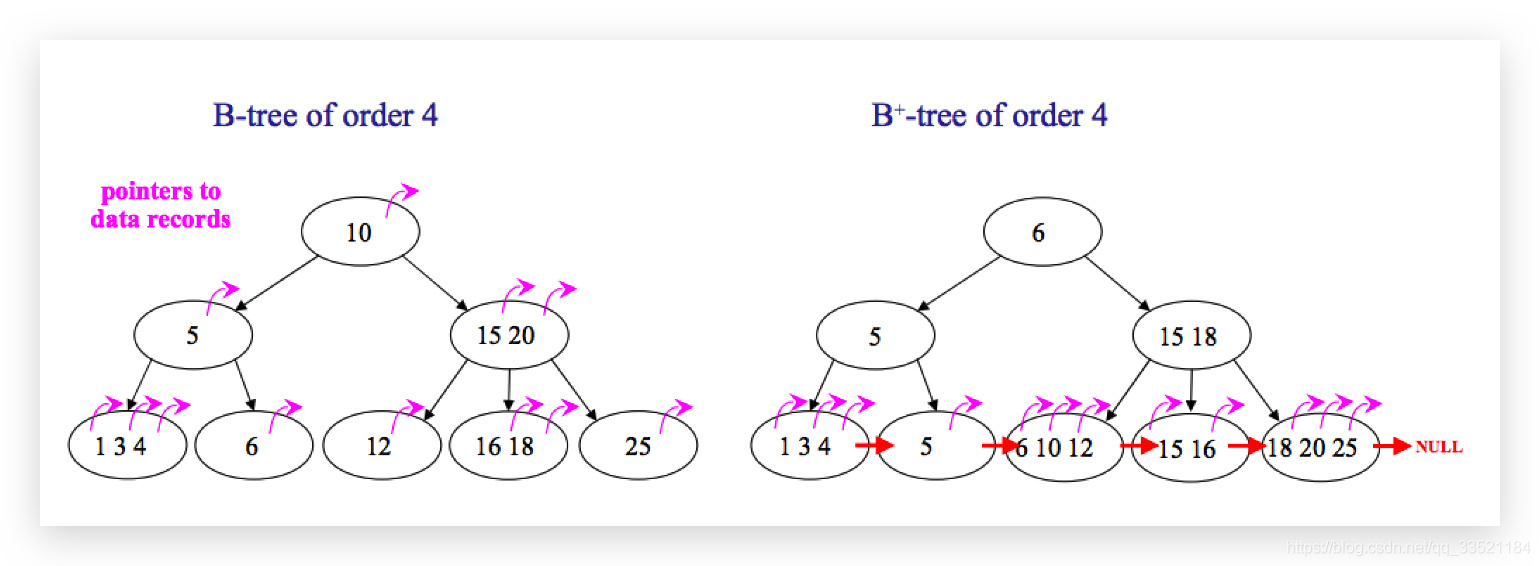
MySQL中的B树索引和B+树索引的区别?
在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
1 使用B树的好处B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
2 使用B+树的好处由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
3 Hash索引和B+树索引有什么区别或者说优劣呢?首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树。 ...
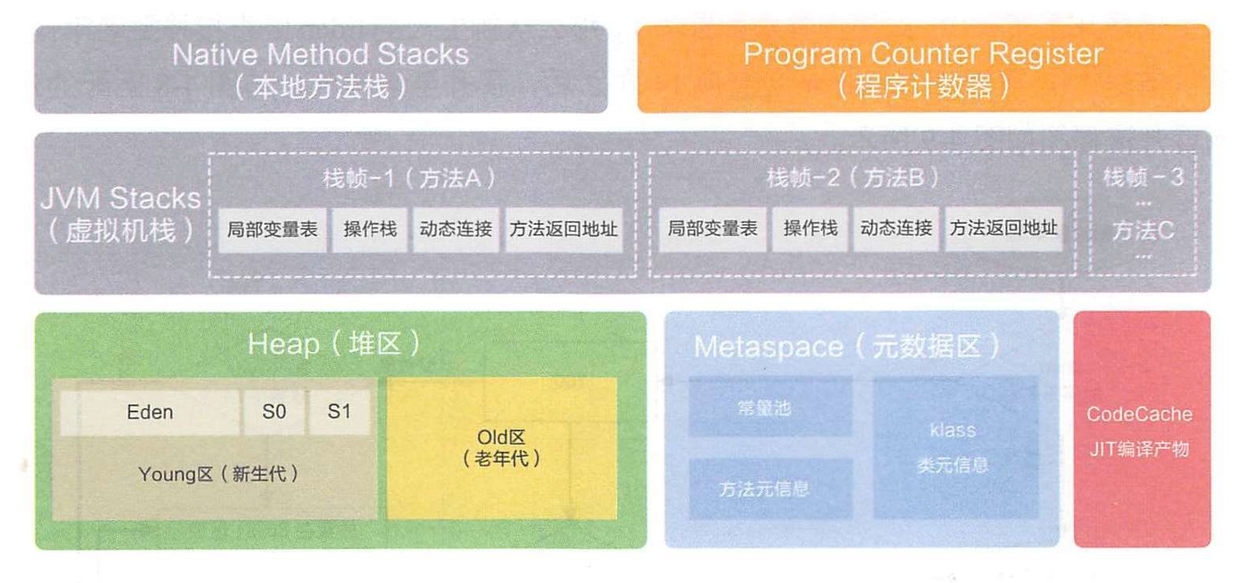
java内存模型
reference page
java虚拟机的内存空间总共分成5个部分:
本地方法栈(Native Method Stacks)
程序计数器(Program Counter Register)
虚拟机栈(JVM Stacks)
堆区(Heap)
方法区(Method Area)
1.1 Program Counter Register(1)定义程序计数器是一块较小的内存空间,可以把它看作当前线程正在执行的字节码的信号指示器。程序计数器里面记录的是当前线程正在执行的那一条字节码指令的地址。 注:如果当前线程正在执行的是一个本地方法,那么此时程序计数器为空。
(2)PCR的作用
字节码解释器通过改变程序计数器来依次执行程序指令,从而实现代码的流程控制,如代码的顺序执行、循环、选择、异常处理等
在多线程情况下,程序计数器用于记录当前线程执行的位置,从而都能在线程被切换回来时能够知道上一次执行的位置,然后接着上一次的执行位置继续执行。
(3)PCR的特点
JVM中内存较小的一块区间
是JVM中唯一一个不抛出OutOfMeneryError异常的区域
线程私有,每一个线程都有一个程序 ...