bash快捷键
| 快捷键 | 作用 |
|---|---|
| crtl+A | 把光标移动到命令行开头,如果我们输入的命令过长,想要把光标移动到命令行开头时使用 |
| crtl+E | 把光标移动到命令行结尾 |
| crtl+C | 强制终止当前的命令 |
| crtl+L | 清屏,相当于clear命令 |
| crtl+U | 删除或剪切光标之前的命令,加入输入了一串很长的命令,不用使用退格键一个一个字符的删除,使用这个命令更加方便 |
| crtl+K | 删除或剪切光标之后的命令 |
| crtl+Y | 粘贴ctrl+U或crtl+K剪切的内容 |
| crtl+R | 在历史命令中搜索,按下crtl+R键之后,就会出现搜索界面,只要输入搜索内容,就会从历史命令中搜索 |
| crtl+D | 推出当前终端 |
| crtl+Z | 暂停,并放入后台,这个快捷键牵扯到工作管理的内容 |
| crtl+S | 暂停屏幕输出 |
| crtl+Q | 恢复屏幕输出 |
1 查看服务器日志
1.1 统计业务接口调用的次数
(1) grep -c
格式:grep -c {关键词} {日志文件}
-c会把所有符合要求的文件都统计出数量结果,不会将所有的日志的数量进行汇总,所以这个命令执行完之后,会得到所有符合要求的文件以及该文件中符合要求的数量,如下所示:
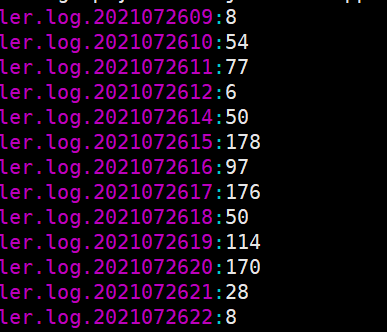
1 | grep -c getInfo /data/nginx/logs/info-2021-07-* |
grep正则表达式:
| 元数据 | 意义和范例 |
|---|---|
^word |
搜寻以word开头的行。 例如:搜寻以#开头的脚本注释行 grep –n ‘^#’ regular.txt |
word$ |
搜寻以word结束的行 |
. |
匹配任意一个字符。 例如:**grep –n ‘e.e’ regular.txt** 匹配e和e之间有任意一个字符,可以匹配eee,eae,eve,但是不匹配ee。 |
\ |
转义字符。 例如:搜寻’,’是一个特殊字符,在正则表达式中有特殊含义。必须要先转义。**grep –n ‘\,” regular.txt** |
\* |
前面的字符重复0到多次。 例如匹配gle,gogle,google,gooogle等等 grep –n ‘go\*gle’ regular.txt |
[list] |
匹配一系列字符中的一个。 例如:匹配gl,gf。**grep –n ‘g[lf]’ regular.txt** |
[n1-n2] |
匹配一个字符范围中的一个字符。 例如:匹配数字字符 grep –n ‘[0-9]’ regular.txt |
[^list] |
匹配字符集以外的字符 例如:**grep –n ‘[^o]‘ regular.txt** 匹配非o字符 |
\<word |
单词是的开头。 例如:匹配以g开头的单词 grep –n ‘\<g’ regular.txt |
word\> |
前面的字符重复n1,n2次 例如:匹配google,gooogle。**grep –n ‘go\{2,3\}gle’ regular.txt** |
\<word |
匹配单词结尾 例如:匹配以tion结尾的单词 grep –n ‘tion\>’ regular.txt |
word\{n1\} |
前面的字符重复n1 例如:匹配google。 grep –n ‘go\{2\}gle’ regular.txt |
word\{n1,\} |
前面的字符至少重复n1 例如:匹配google,gooogle。 grep –n ‘go\{2\}gle’ regular.txt |
word\{n1,n2\} |
前面的字符重复n1,n2次 例如:匹配google,gooogle。 grep –n ‘go\{2,3\}gle’ regular.txt |
(2) grep与wc -l结合
格式:grep {关键词} {日志文件} | wc -l
这个命令会把所有符合要求的文件中的统计数量进行汇总求和,所有这个命令执行完之后,会得到一个数字。
1 | grep getInfo /data/nginx/logs/info-2021-07-* | wc -l |
(3) zgrep
格式:zgrep {关键词} {日志文件} | wc -l
由于日志文件可能会很大,很多公司会每天按照大小进行切分,并以压缩格式保存,这类文件就需要使用zgrep命令进行统计。
1 | root@iZbp1crt1zqre1ar8:/HD/logs/punchout# zgrep -c 'TraceLogProviderFilter' punchout.2020-02-23_1.log.gz |
(4) 按照正则匹配所有接口形式的调用
正则表达式形式如下:
1 | awk '{match($0, /\/[a-zA-Z]+\/[a-zA-Z]+/, a); print a[0];}' |
命令如下:
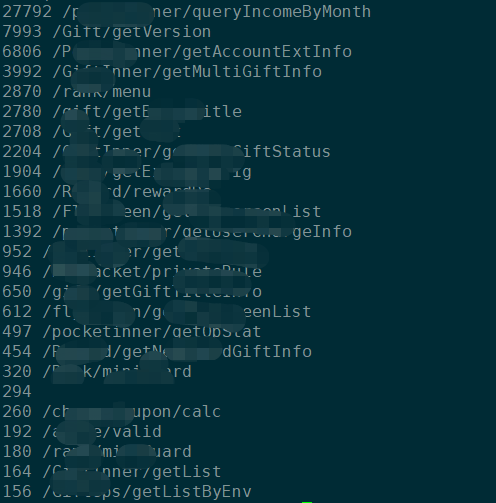
1 | cat log.2021081916 | awk '{match($0, /\/[a-zA-Z]+\/[a-zA-Z]+/, a); print a[0];}' | sort | uniq -c | sort -n -r |

(5) 统计调用次数大于n的接口
先整理出所有接口被调用的次数,然后再使用awk对所有接口和调用次数进行遍历,筛选出所有调用次数大于n的接口即可。
1 | cat log.20210819 | awk '{match($0, /\/[a-zA-Z]+\/[a-zA-Z]+/, a); print a[0];}' | sort | uniq -c | sort -n -r | awk -F " " '{if ($1>100) print $1, $2}' |
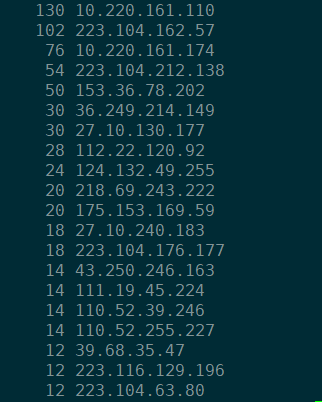
1.2 统计访问IP的次数
首先查看日志的格式,可以按照空格进行切割,然后对切割完的结果进行排序,使用sort命令,最后在使用uniq命令,去除一些重复的行
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入。
语法格式:sort [参数] [文件]
常用参数:
-b 忽略每行前面开始出的空格字符 -c 检查文件是否已经按照顺序排序 -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符 -f 排序时,将小写字母视为大写字母 -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符 -m 将几个排序号的文件进行合并 -M 将前面3个字母依照月份的缩写进行排序 -n 依照数值的大小排序 -o <输出文件> 将排序后的结果存入制定的文件 -r 以相反的顺序来排序 -t <分隔字符> 指定排序时所用的栏位分隔字符 -k 指定需要排序的栏位 uniq命令全称是“unique”,中文释义是“独特的,唯一的”。该命令的作用是用来去除文本文件中连续的重复行,中间不能夹杂其他文本行。去除了重复的,保留的都是唯一的,也就是独特的,唯一的了。
我们应当注意的是,它和sort的区别,sort只要有重复行,它就去除,而uniq重复行必须要连续,也可以用它忽略文件中的重复行。
语法格式:uniq [参数] [文件]
常用参数:
-c 打印每行在文本中重复出现的次数 -d 只显示有重复的纪录,每个重复纪录只出现一次 -u 只显示没有重复的纪录
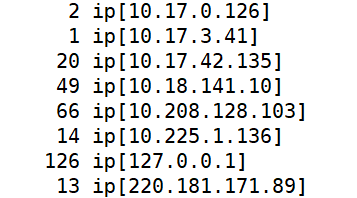
知道IP在哪个位置:
1
cat log.2021073016-20210730 | awk -F' ' '{print $4}' | sort | uniq -c
不知道IP在哪个位置,采用正则匹配
1
cat log.2021073016-20210730 | awk --re-interval '{match($0, /([0-9]{1,3}\.){3}[0-9]{1,3}/, a); print a[0]}' | sort | uniq -c | sort -n -r
2 查看服务器负载
服务器负载一般指的是Linux服务器的CPU、内存、IO等的负载。
(1) uptime-查看系统负载
Linux系统中的uptime命令主要用于获取主机运行时间和查询Linux系统负载等信息。
uptime命令可以显示系统已经运行了多长时间,信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登录用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。 uptime命令用法十分简单,直接输入uptime即可查看系统负载情况。
语法格式:uptime [参数]
常用参数:
| -p | 以漂亮的格式显示机器正常运行的时间 |
|---|---|
| -s | 系统自开始运行时间,格式为yyyy-mm-dd hh:mm:ss |
| -h | 显示帮助信息 |
1 | [root@localhost ~]# uptime |
(2) w-显示已登录用户
w命令用于显示已经登陆系统的用户列表,并显示用户正在执行的指令。执行这个命令可得知目前登入系统的用户有哪些人,以及他们正在执行的程序。单独执行w命令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
语法格式:w [参数]
常用参数:
| -h/–no-header | 不打印头信息 |
|---|---|
| -u/–no-current | 当显示当前进程和cpu时间时忽略用户名 |
| -s/–short | 使用短输出格式 |
| -f/–from | 显示用户从哪登录 |
| -o/–old-style | 老式输出 |
| -i/–ip-addr | 显示IP地址而不是主机名(如果可能) |
| –help | 显示此帮助并退出 |
| -V/–version | 显示版本信息 |
1 | [root@localhost ~]# w |
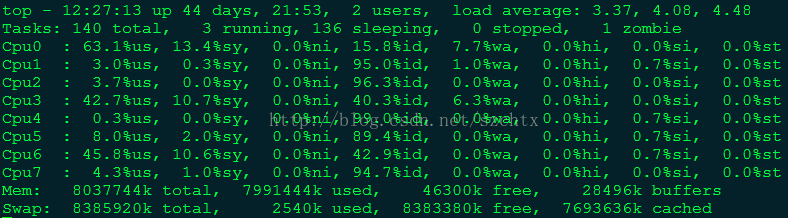
(3) top-实时显示进程动态
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析。
在top命令中按f按可以查看显示的列信息,按对应字母来开启/关闭列,大写字母表示开启,小写字母表示关闭。带*号的是默认列。
语法格式:top [参数]
常用参数:
| -d | 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s |
|---|---|
| -q | 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行 |
| -c | 切换显示模式 |
| -s | 安全模式,将交谈式指令取消, 避免潜在的危机 |
| -i | 不显示任何闲置 (idle) 或无用 (zombie) 的行程 |
| -n | 更新的次数,完成后将会退出 top |
| -b | 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内 |
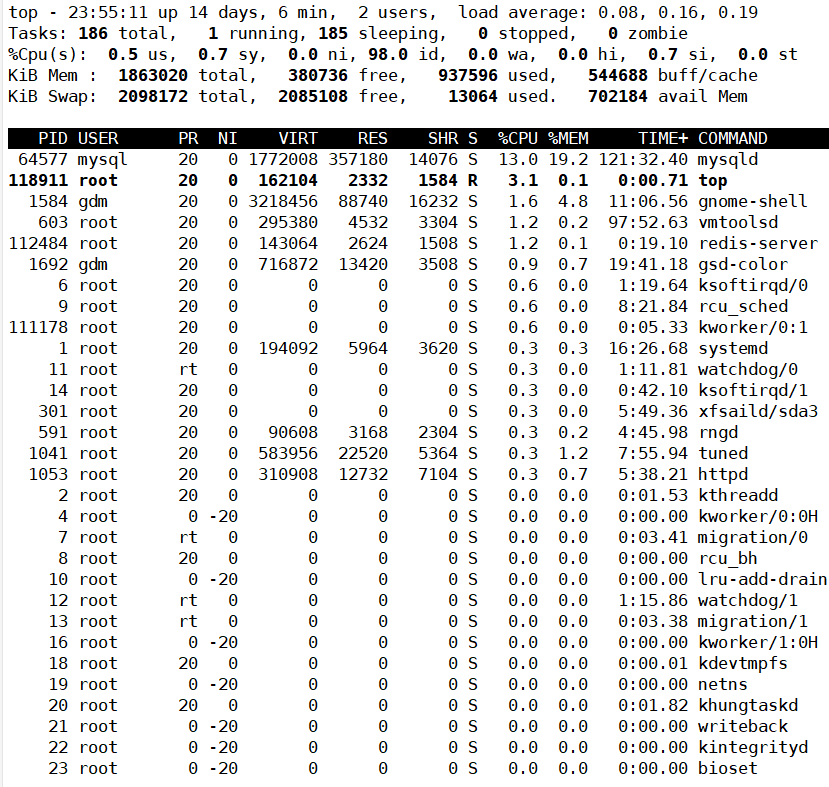
其中,统计信息区前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
2
3
4
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
running 正在运行的进程数
sleeping 睡眠的进程数
stopped 停止的进程数
zombie 僵尸进程数
Cpu(s):
0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0%hi:硬件CPU中断占用百分比
0.0%si:软中断占用百分比
0.0%st:虚拟机占用百分比最后两行为内存信息,内容如下:
2
3
4
5
6
7
8
9
10
191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap:
192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。进程信息区统计信息区域的下方显示了各个进程的详细信息。各列的含义:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。其他实用命令:
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。top命令常用操作:
2
3
4
5
top -d 2 //每隔2秒显式所有进程的资源占用情况
top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况
top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
查看CPU个数
在top界面下,按下1,即可查看cpu个数。
(4) iostat-监视系统输入输出设备和CPU的使用情况
iostat被用于监视系统输入输出设备和CPU的使用情况。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。
语法格式: iostat [参数] [设备]
常用参数:
| -c | 仅显示CPU使用情况 |
|---|---|
| -d | 仅显示设备利用率 |
| -k | 显示状态以千字节每秒为单位,而不使用块每秒 |
| -m | 显示状态以兆字节每秒为单位 |
| -p | 仅显示块设备和所有被使用的其他分区的状态 |
| -t | 显示每个报告产生时的时间 |
(5) mpstat
mpstat mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
再来看看 oschina 上的 mpstat 命令执行结果:

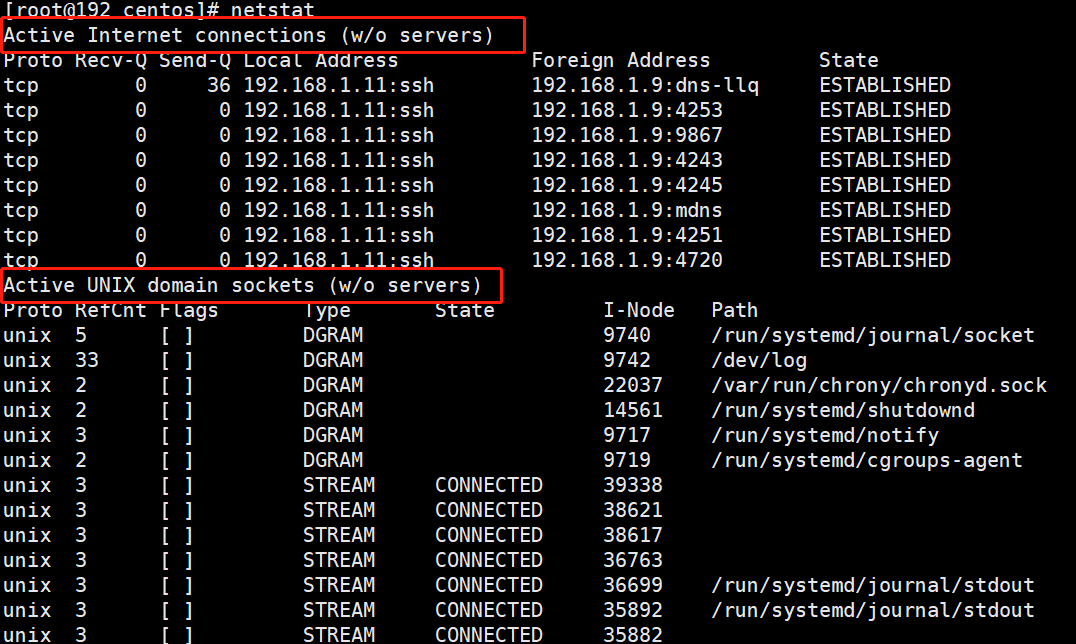
(6) netstat
Netstat 和 ps 命令类似,是 Linux 管理员基本上每天都会用的工具,它显示了大量跟网络相关的信息,例如 socket 的使用、路由、接口、协议、网络等等,下面是一些常用的参数:
-aShow all socket information- -
rShow routing information -iShow network interface statistics-sShow network protocol statistics
(7) nmon
Nmon, 是 Nigel’s Monitor 的缩写,是一个使用很普遍的开源工具,用以监控 Linux 系统的性能。Nmon 监控多个子系统的性能数据,例如处理器的使用率、内存使用率、队列、磁盘I/O统计、网络I/O统计、内存页处理和进程信息。Nmon 也提供了一个图形化的工具。
要运行 nmon,你可以在命令行中启动它,然后选择要监控的子系统,这些子系统都对应有一个快捷键,例如输入 c 可查看 CPU 信息,m用于查看内存,d用来查看磁盘信息等,你也可以使用 -f 命令将 nmon 的执行结果保存到一个 CSV 文件中,便于日后分析。在每日的监控工作中,我发现 nmon 是我最常用的工具。
nmon不是Linux系统自带的命令,需要进行安装,安装命令如下:
1 | yum install nmon |
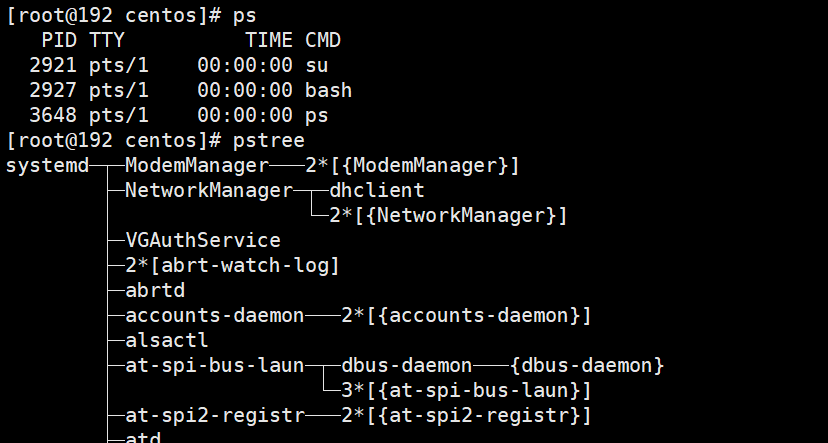
(8) ps|pstree
ps 和 pstree 命令是 Linux 系统管理员最好的朋友,都可以用来列表正在运行的所有进程。ps 告诉你每个进程占用的内存和 CPU 处理时间,而 pstree 显示的信息没那么详细,但它以树形结构显示进程之间的依赖关系,包括子进程信息。一旦发现某个进程有问题,你可以使用 kill 来杀掉它。
1 | kill pid # kill a process |
(9) sar-系统运行状态统计
该命令号称系统监控的瑞士军刀,目前Linux上最为全面的系统性能分析工具之一,可以从14个大方面对系统的活动进行报告,包括文件的读写情况、系统调用的使用情况、串口、CPU效率、内存使用状况、进程活动及IPC有关的活动等,使用也是较为复杂。
sar 默认显示的是从零点开始每隔十分钟到现在的CPU情况,如果是查看之前的报告,需要指定日志报告,sar -f /var/log/sysstat/sa25 。
解释下各列的指标:
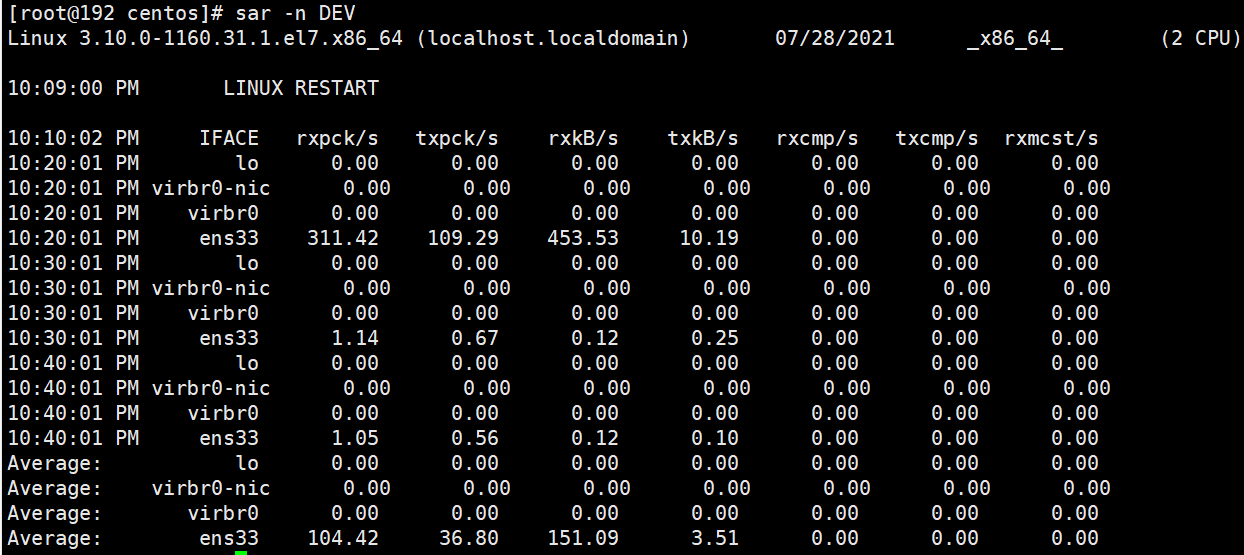
%user 用户模式下消耗的CPU时间的比例;
%nice 通过nice改变了进程调度优先级的进程,在用户模式下消耗的CPU时间的比例
%system 系统模式下消耗的CPU时间的比例;
%iowait CPU等待磁盘I/O导致空闲状态消耗的时间比例;
%steal 利用Xen等操作系统虚拟化技术,等待其它虚拟CPU计算占用的时间比例;
%idle CPU空闲时间比例;

查看内存使用情况:
1
sar -r

查看带宽
1
sar -n DEV
tips
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来;
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
Reference
- https://blog.csdn.net/pjx827480541/article/details/104457511
- Linux查看机器负载
- https://cloud.tencent.com/developer/article/1533965
- https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316399.html
写在最后
欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。
 wechat
wechat alipay
alipay bitcoin
bitcoin