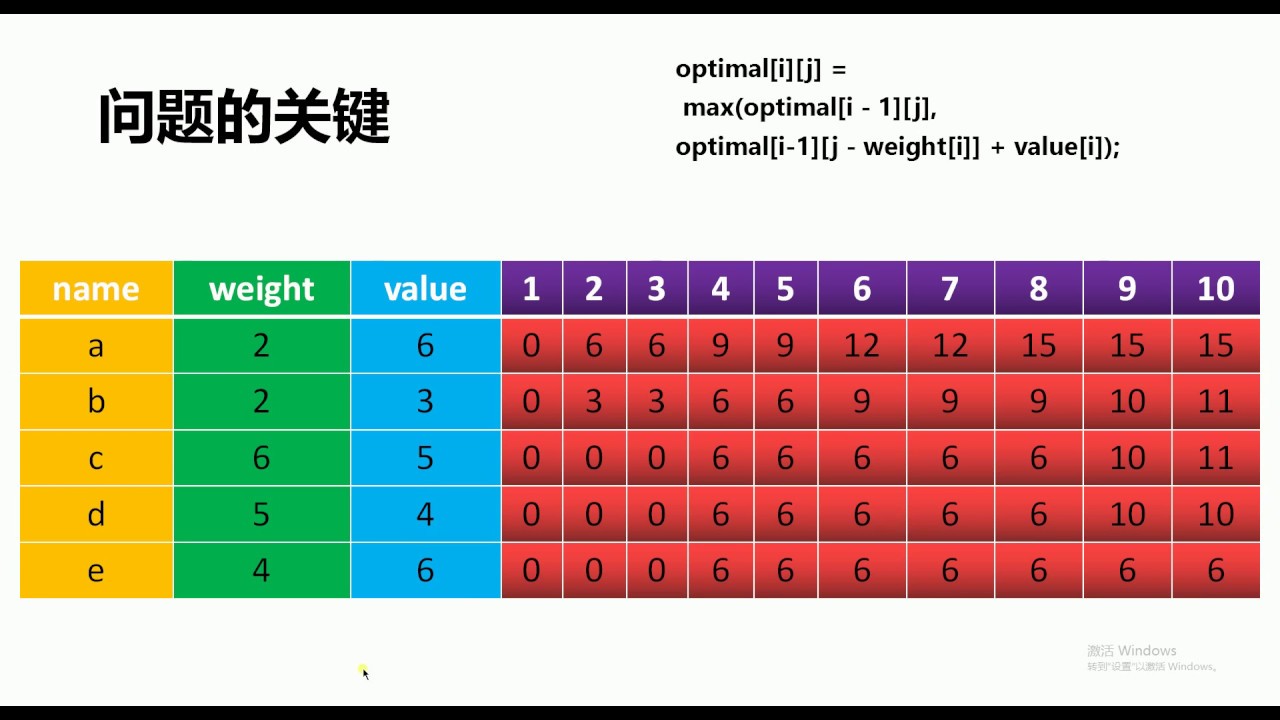
1 二者区别
1.1 HashMap部分源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class HashMap <K,V> extends AbstractMap <K,V> implements Map <K,V>, Cloneable, Serializable { public HashMap () { this .loadFactor = DEFAULT_LOAD_FACTOR; } public V get (Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } public V remove (Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null , false , true )) == null ? null : e.value; } public boolean isEmpty () { return size = = 0 ; } public int size () { return size; } public boolean containsKey (Object key) { return getNode(hash(key), key) != null ; } public boolean containsValue (Object value) { Node<K,V>[] tab; V v; if ((tab = table) != null && size > 0 ) { for (int i = 0 ; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null ; e = e.next) { if ((v = e.value) == value || (value != null && value.equals(v))) return true ; } } } return false ; } }
1.2 HashTable部分源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 public class Hashtable <K,V> extends Dictionary <K,V> implements Map <K,V>, Cloneable, java.io.Serializable { public Hashtable () { this (11 , 0.75f ); } public synchronized V put (K key, V value) { if (value == null ) { throw new NullPointerException (); } Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for (; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null ; } public synchronized V remove (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> e = (Entry<K,V>)tab[index]; for (Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { modCount++; if (prev != null ) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null ; return oldValue; } } return null ; } public synchronized boolean isEmpty () { return count = = 0 ; } public synchronized int size () { return count; } public synchronized boolean containsKey (Object key) { Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF ) % tab.length; for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return true ; } } return false ; } public boolean containsValue (Object value) { return contains(value); } public synchronized boolean contains (Object value) { if (value == null ) { throw new NullPointerException (); } Entry<?,?> tab[] = table; for (int i = tab.length ; i-- > 0 ;) { for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) { if (e.value.equals(value)) { return true ; } } } return false ; } }
一些资料建议,当需要同步时,用Hashtable,反之用HashMap。但是,因为在需要时,HashMap可以被同步,HashMap的功能比Hashtable的功能更多,而且它不是基于一个陈旧的类的,所以有人认为,在各种情况下,HashMap都优先于Hashtable。
reference https://blog.csdn.net/u010983881/article/details/49762595
https://www.jianshu.com/p/5c34133ed372
写在最后 欢迎大家关注鄙人的公众号【麦田里的守望者zhg】,让我们一起成长,谢谢。

 wechat
wechat alipay
alipay bitcoin
bitcoin